Created a tool that estimates data science salaries to help data scientists negotiate their income when they get a job. Scraped over sample of job descriptions from glassdoor using python and selenium. Engineered features from the text of each job description to quantify the value companies put on different Data-Science tools like python, excel, aws, and spark. Optimized Linear, Lasso, and Random Forest Regressors using GridsearchCV to reach the best model. Built a client facing API using flask.
- Python Version:3.8
- Packages: pandas, numpy, sklearn, matplotlib, seaborn, selenium, flask, json, pickle
- For Web Framework Requirements: pip install -r requirements.txt
- Special Thanks to KenJee Github: https://github.com/PlayingNumbers
- Tutorial(youtube) : https://www.youtube.com/watch?v=GmW4F6MHqqs&list=PL2zq7klxX5ASFejJj80ob9ZAnBHdz5O1t
- & Thanks to Ömer SakaryaScraper Github: https://github.com/arapfaik/scraping-glassdoor-selenium
- Scraper Article: https://towardsdatascience.com/selenium-tutorial-scraping-glassdoor-com-in-10-minutes-3d0915c6d905
- Flask Productionization: https://towardsdatascience.com/productionize-a-machine-learning-model-with-flask-and-heroku-8201260503d2
- Web Scraping
This is the first step where the script is written to pull-out the information available on web-page(information stored by web-elements and fields: -span,div, li, etc.)of the website. After pulling out the information it is stored in file for further processing.
P.S: the code has been modified according to the updated structure of the website for webscraping, there are fields/data that I couldn't able to find, for reading purposes the old lines of code is commented and updated code added underneath for better understanding.please take a note that I have changed the names of the column and files according to my need, if you are copy pasting this code you have to look for syntax errors in names of files and data-columns that are used in tutorial.
- glassdoor_scrapper.py (this is the modified version for re-structured website) click the link below:
- https://github.com/wizrox/dsSlryProj/blob/master/glassdoor_scrapper.py
After scraping the data, It has to be clean and arrange to select the information suitable for Data EDA(Exploration and Data Analysis). this is done through the script which drop the redundant and excessive tables and keep the valid data/fields in column. upon the extraction of the necessary data , it will be stored in another csv file for further computation and processing.
After getting the relevant information in the form of data-set, There will be applied computational and mathemetical formulas to analyze the patterns and accuracy of the information, there are various techniques used to find out the accurate prediction of the result. after listing the comparison of the output from different models and techniques. A 'pickle' file is created whcih will be imported later on to used with different application scenario like client/server or service call to API.
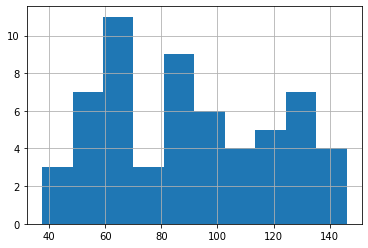
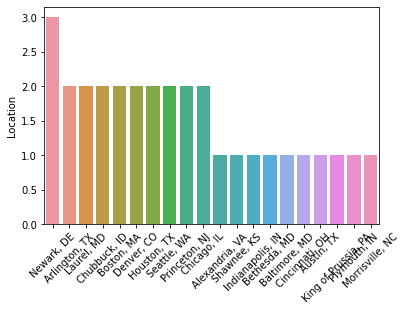
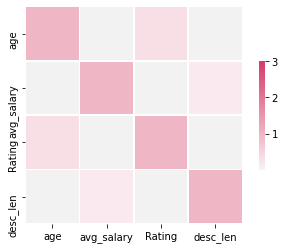
After making a pickle file, to implement it in a client/server scenario, Flask API is downloaded and used to stimulate as a local server for listening to client request.
#Resources:
https://www.youtube.com/watch?v=GmW4F6MHqqs&list=PL2zq7klxX5ASFejJj80ob9ZAnBHdz5O1t
https://towardsdatascience.com/selenium-tutorial-scraping-glassdoor-com-in-10-minutes-3d0915c6d905