A RAG system for searching through research papers and answering questions about them. Runs entirely locally via Ollama, tries to avoid making stuff up by verifying claims against the source documents, and shows you exactly where each answer comes from.

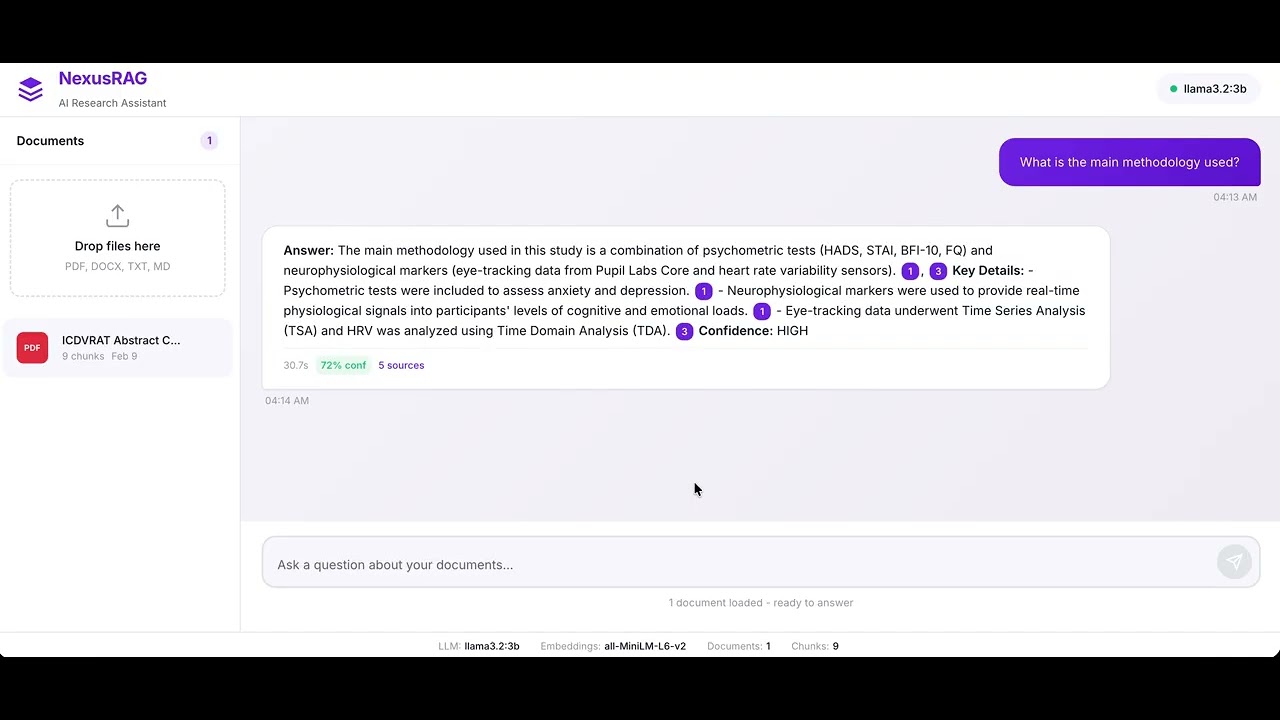
You upload research papers (PDF, DOCX, TXT, MD). NexusRAG parses and chunks them, stores embeddings in LanceDB, and builds a BM25 keyword index alongside it. When you ask a question, a hybrid retriever combines semantic search with keyword matching to find the most relevant passages. Those go to a local LLM (via Ollama) which generates an answer with inline citations. Before returning, a verification step checks each citation against the source — if something doesn't hold up, it reformulates the query, re-retrieves, and tries again.
- Tries to avoid hallucinations — Self-correcting retrieval loop verifies claims against the actual documents
- Shows where answers come from — Every claim links to exact passages and page numbers
- Runs locally — Everything stays on your machine via Ollama, no API keys needed
- Works across papers — Can pull together and connect info from multiple documents
git clone https://github.com/urme-b/NexusRAG.git
cd NexusRAG
python -m venv .venv && source .venv/bin/activate
pip install -e .
# Start Ollama (separate terminal)
ollama serve
ollama pull llama3.2:3b
# Launch NexusRAG
make run
# → http://localhost:8000| Model | Size | RAM needed | Speed | Best for |
|---|---|---|---|---|
llama3.2:3b |
2 GB | 8 GB | Fast | Quick queries, basic summarization |
llama3.1:8b |
4.9 GB | 16 GB | Moderate | Complex multi-document analysis |
Switch models by updating the config — see configs/ for details.
Python · FastAPI · LanceDB · Ollama · Sentence Transformers
- Python 3.11+
- 8 GB RAM minimum (16 GB recommended for larger models)
- Ollama installed and running
- Latency reduction for real-time querying
- Multimodal support (tables, figures, charts from PDFs)
- Collaborative knowledge base for research teams
- Streaming responses in the web interface
- Support for additional LLM providers beyond Ollama
- Batch ingestion with progress tracking
- Export citations in standard formats (BibTeX, APA)