![]()
Early-stop decision gating for LLM model migrations.
v0.11.1 alpha CLI for sampling migration candidates before you commit to a full evaluation.
Current status · Quickstart · How it works · Corpus format · Roadmap
You want to migrate from one LLM to another: cheaper, faster, better, self-hosted, or more private.
So you run your full prompt corpus against the candidate model. Hundreds or thousands of API calls. Hours of waiting. And only at the end do you discover the candidate breaks the categories that matter most.
You just burned budget to learn something you could have known in the first 10-20%.
Driftcut is the test you run before the full evaluation. It samples strategically, compares baseline and candidate on a representative slice, runs deterministic checks first, sends only ambiguous prompts to a judge model, and tells you whether to STOP, CONTINUE, or PROCEED.
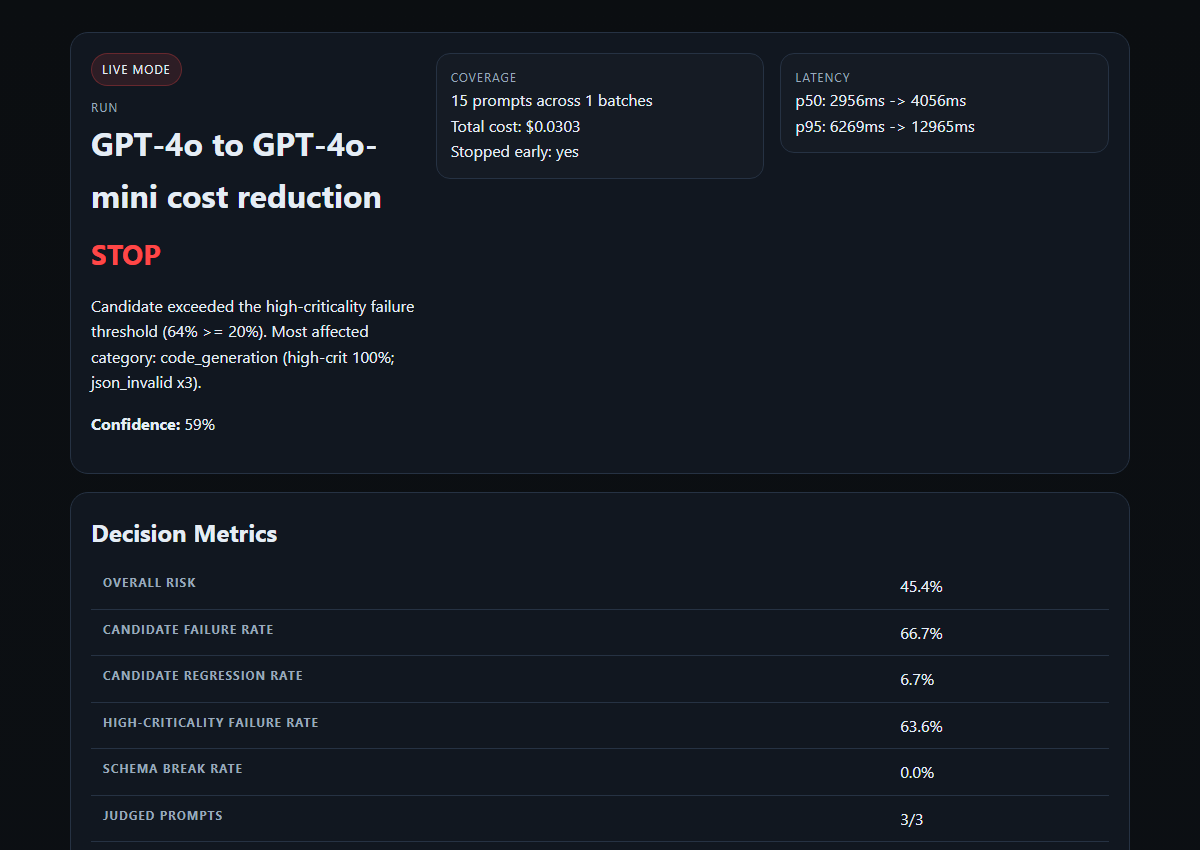
HTML report from a real migration test: GPT-4o → GPT-4o-mini (15 prompts, $0.03, stopped in 1 batch)
Driftcut is not a generic eval framework. It does not replace Promptfoo, DeepEval, or your internal eval suite. It sits one step earlier in the workflow: the filter that decides whether a full evaluation is worth the money.
| Driftcut is | Driftcut is not |
|---|---|
| A pre-evaluation filter | A generic eval framework |
| A migration decision layer | An experiment tracker |
| A budget-aware canary | A prompt optimization tool |
| CLI-first and single-purpose | A dashboard-first platform |
Today, Driftcut can:
- Validate a structured corpus and migration config
- Build stratified batches that prioritize high-criticality prompts
- Run baseline and candidate models concurrently via LiteLLM
- Retry transient rate limits, timeouts, connection failures, and 5xx responses before counting an API error
- Replay historical paired outputs through the same deterministic checks, judge flow, and decision engine
- Run deterministic checks for format, JSON validity, required content, and output limits
- Send ambiguous prompts to a judge model for semantic comparison
- Escalate from a light judge to a heavy judge when confidence is low (tiered strategy)
- Track latency, baseline/candidate cost, and judge cost
- Optionally reuse cached baseline responses and persist run history to Redis
- Produce
STOP,CONTINUE, orPROCEEDdecisions during the run - Export both JSON results and an HTML report
- Summarize deterministic and semantic failure archetypes such as
json_invalid,missing_json_keys,refusal_regression, andinstruction_miss - Show per-category quality scorecards in JSON and HTML outputs
- Explain final decisions with category-aware risk summaries instead of only threshold math
- Scaffold a new project with
driftcut init(generates a working config and sample corpus) - Bootstrap a structured corpus from raw prompts with
driftcut bootstrap(LLM-powered classification) - Compare two runs with
driftcut diffto see what changed between migration attempts
pip install driftcutWant to see what Driftcut actually tells you? The examples/demo/ walkthrough reproduces a real gpt-4o cost-cut decision against two cheaper candidates, fully offline and without an API key.
For Redis-backed memory support:
pip install "driftcut[redis]"git clone https://github.com/riccardomerenda/driftcut.git
cd driftcut
pip install -e .For local Redis-memory testing without Docker:
pip install -e ".[dev,redis]"The fastest way to get started:
driftcut initThis creates a working migration.yaml and prompts.csv in the current directory. You can customize the models:
driftcut init --baseline azure/gpt-4-turbo --candidate openrouter/mistral-largeIf you already have prompts but they aren't categorized:
driftcut bootstrap --input raw-prompts.txt --output prompts.csvThis sends your prompts to an LLM that classifies each one with a category, criticality, and expected output type. Accepts .txt (one per line), .csv (with a prompt column), or .json. Review the output and edit as needed.
driftcut bootstrap --input prompts.json --model openai/gpt-4.1-mini --output prompts.csv# migration.yaml
name: "GPT-4o to Claude Haiku migration gate"
models:
baseline:
provider: openai
model: gpt-4o
candidate:
provider: anthropic
model: claude-haiku
corpus:
file: prompts.csv
sampling:
batch_size_per_category: 3
max_batches: 5
min_batches: 2
evaluation:
judge_strategy: tieredValidate first, then run:
driftcut validate --config migration.yaml
driftcut run --config migration.yamldriftcut run now:
- executes sampled batches,
- applies deterministic checks,
- judges ambiguous prompts,
- decides whether to stop, continue, or proceed,
- writes
driftcut-results/results.json, - writes
driftcut-results/report.html.
driftcut replay uses the same decision layer on historical paired outputs:
driftcut replay --config examples/replay.yaml --input examples/replay.jsonReplay is intentionally narrow: it accepts a canonical paired-output JSON contract, not arbitrary vendor exports.
Works with any LiteLLM-supported provider: OpenAI, Anthropic, OpenRouter, Azure, self-hosted, and more.
If you want a reproducible local stack for testing the optional memory layer, Driftcut now includes a Dockerfile and docker-compose.yml.
The Compose stack uses redis/redis-stack-server because Driftcut's memory layer relies on Redis JSON and Search commands.
Start Redis and validate the sample config:
docker compose up -d redis
docker compose run --rm driftcut driftcut validate --config examples/migration.yamlTo exercise the Redis-backed baseline cache and run history:
docker compose run --rm driftcut driftcut run --config examples/migration.redis.yaml
docker compose run --rm driftcut driftcut run --config examples/migration.redis.yamlThe second run should report baseline cache hits in the terminal summary and in driftcut-results/results.json.
You can also run the test suite inside the container:
docker compose run --rm driftcut python -m pytestDocker is optional. The normal local Python workflow remains first-class.
Example terminal output:
$ driftcut run --config migration.yaml
GPT-4o to Claude Haiku migration gate
Mode: live
Baseline: openai/gpt-4o
Candidate: anthropic/claude-haiku
Batch 1: 12 prompts, 0 API errors, $0.1840 cumulative
Decision: CONTINUE (58% confidence)
Judge coverage: 3/3 ambiguous prompts
Risk is still borderline after the first sampled batch.
Batch 2: 12 prompts, 0 API errors, $0.3120 cumulative
Decision: PROCEED (82% confidence)
Judge coverage: 4/4 ambiguous prompts
Risk stayed below the configured proceed threshold.
Run complete
Prompts tested: 24/30
Batches tested: 2
Total cost: $0.3120
Judge cost: $0.0280
Latency p50: 910ms (baseline) -> 690ms (candidate)
Latency p95: 1480ms (baseline) -> 1100ms (candidate)
Decision: PROCEED (82% confidence)
Reason: Risk stayed below the configured proceed threshold.
Top category: extraction (11% risk | json_invalid x2)
Example driftcut-results/results.json excerpt:
{
"mode": "live",
"decision": {
"outcome": "PROCEED",
"confidence": 0.82,
"reason": "Risk stayed below the configured proceed threshold."
},
"decision_history": [
{
"outcome": "PROCEED",
"metrics": {
"category_scores": [
{
"category": "extraction",
"overall_risk": 0.11,
"archetypes": {
"json_invalid": 2
}
}
]
}
}
],
"cost": {
"baseline_usd": 0.184,
"candidate_usd": 0.1,
"judge_usd": 0.028,
"total_usd": 0.312
},
"batches": [
{
"batch_number": 1,
"results": [
{
"prompt_id": "cx-001",
"candidate": {
"latency_ms": 640.0,
"retry_count": 1,
"cost_usd": 0.009,
"error": null
}
}
]
}
]
}The HTML report summarizes the same run-level decision, threshold context, failure archetypes, and prompt examples in a shareable format.
Your prompt corpus
|
v
Stratified sampling by category and criticality
|
v
Run baseline and candidate on sampled batches
|
v
Deterministic checks:
- expected format
- JSON validity / required keys
- required / forbidden content
- max output length
|
v
Judge ambiguous prompts only
|
v
Track latency and cost
|
v
Decision engine
|
v
STOP / CONTINUE / PROCEED
|
v
JSON + HTML report
Deterministic checks
+
Light judge on ambiguous prompts
+
Heavy escalation when evidence stays unclear
->
Higher-confidence migration decisions
Driftcut is designed around three migration dimensions:
- Quality - deterministic checks are live, and a light judge now handles ambiguous prompts.
- Latency - p50 and p95 are tracked and fed into the decision engine.
- Cost - spend is tracked per run, including judge cost.
The current alpha can classify failures such as:
| Archetype | What it means |
|---|---|
api_error |
Model call failed |
empty_output |
Response is empty |
json_invalid |
Output is not valid JSON |
missing_json_keys |
Required JSON keys are missing |
invalid_labels |
Label output could not be parsed |
missing_required_content |
Required substring was not found |
forbidden_content |
Forbidden substring was found |
overlong_output |
Output exceeded max_output_chars |
refusal_regression |
Candidate refused or deflected a task the baseline completed |
instruction_miss |
Candidate missed the core instruction even though it stayed syntactically valid |
incomplete_answer |
Candidate response dropped useful detail or coverage relative to baseline |
format_drift |
Candidate drifted away from the expected presentation or structure |
hallucination_risk |
Judge flagged unsupported or fabricated content risk |
semantic_regression |
Candidate was materially worse in meaning, but no more specific semantic bucket applied |
Driftcut requires a structured corpus.
id,category,prompt,criticality,expected_output_type,notes,required_substrings,forbidden_substrings,json_required_keys,max_output_chars
cx-001,customer_support,"Given this ticket: {ticket}, draft a response.",high,free_text,,refund|replacement,,,
ex-001,structured_extraction,"Extract entities from: {text}. Return JSON.",high,json,,,,"persons|organizations|locations",
cl-001,classification,"Classify this review: {review}",medium,labels,,,,,
su-001,summarization,"Summarize this document: {doc}",low,markdown,,,,1200| Field | Type | Required | Notes |
|---|---|---|---|
id |
string | yes | Unique identifier |
category |
string | yes | Example: customer_support, structured_extraction |
prompt |
string | yes | Prompt to execute |
criticality |
enum | yes | low / medium / high |
expected_output_type |
enum | yes | free_text / json / labels / markdown |
notes |
string | no | Optional human context |
required_substrings |
list-like string | no | ` |
forbidden_substrings |
list-like string | no | ` |
json_required_keys |
list-like string | no | Keys that must exist in parsed JSON |
max_output_chars |
int | no | Hard upper bound for deterministic length checks |
The runtime actively uses sampling, risk, latency, output, and evaluation.judge_strategy. The active strategies are none, light, tiered, and heavy. tiered calls the light judge first and escalates to the heavy judge when confidence is below tiered_escalation_threshold.
name: "OpenAI to Anthropic migration gate"
description: "Early-stop migration decision support for support and extraction workloads"
models:
baseline:
provider: openai
model: gpt-4o
candidate:
provider: anthropic
model: claude-haiku
corpus:
file: prompts.csv
sampling:
batch_size_per_category: 3
max_batches: 5
min_batches: 2
risk:
high_criticality_weight: 2.0
stop_on_schema_break_rate: 0.25
stop_on_high_criticality_failure_rate: 0.20
proceed_if_overall_risk_below: 0.08
evaluation:
judge_strategy: tiered
judge_model_light: openai/gpt-4.1-mini
judge_model_heavy: openai/gpt-4.1
tiered_escalation_threshold: 0.6
detect_failure_archetypes: true
latency:
track: true
regression_threshold_p50: 1.5
regression_threshold_p95: 2.0
output:
save_json: true
save_html: true
save_examples: true
show_thresholds: true
show_confidence: true
memory:
backend: redis
redis_url: redis://localhost:6379/0
namespace: driftcut-dev
response_cache:
enabled: true
ttl_seconds: 604800
run_history:
enabled: true
ttl_seconds: 2592000When memory.backend=redis is enabled, Driftcut can:
- reuse cached baseline responses across repeated live runs
- keep searchable run documents in Redis
- disclose cache hits, misses, and saved baseline cost in JSON and HTML outputs
Cached baseline responses are intentionally excluded from live latency comparison so cache reuse does not make the candidate appear artificially faster.
Driftcut aims to save budget, so the judge cannot consume all of it.
| Stage | Method | Cost | Catches |
|---|---|---|---|
| First pass | Deterministic checks | $0 | Format, schema, content, and output-limit failures |
| Ambiguous prompts | Light judge | Low | Semantic quality differences where both outputs still pass deterministic checks |
| Low-confidence cases | Heavy escalation (tiered) | Higher | Cases where the light judge's confidence is below the escalation threshold |
- Concept document
- Demo config and corpus
- Config loader + corpus loader (CSV, JSON)
- Stratified batch sampler
-
driftcut validatecommand - Async model execution via LiteLLM
-
driftcut runcommand with concurrent execution - Latency tracker (p50, p95 per category)
- Cost tracker (per-prompt and cumulative)
- JSON export
- Multi-provider support (OpenRouter, Azure, custom endpoints)
- Deterministic checker
- Failure archetype summary
- Decision engine with configurable thresholds
- HTML report
- Light judge integration for ambiguous prompts
- Tiered judging with light-to-heavy escalation
- Historical replay mode for paired-output backtesting
- Redis memory for baseline caching and run-history persistence
- Docker + Redis local dev stack
- Richer failure archetypes
- Per-category quality scorecards
- PyPI package publish
-
driftcut initscaffolding command -
driftcut bootstrapcorpus generator -
driftcut diffrun comparison - Public benchmark demo (
examples/demo/)
Full roadmap: docs.driftcut.dev/roadmap
Python 3.12 · Typer · LiteLLM · Rich · Pydantic · YAML
Driftcut answers a narrower question than generic eval tooling:
"Should we continue this migration, or are we already seeing enough risk to stop?"
That narrow scope is the product wedge.
- GitHub: riccardomerenda/driftcut
- Docs: docs.driftcut.dev
- Landing page: driftcut.dev
MIT