基于 Qwen-TTS API 的功能丰富的语音合成 FastAPI 应用,支持中英双语及中文方言的智能语音合成。
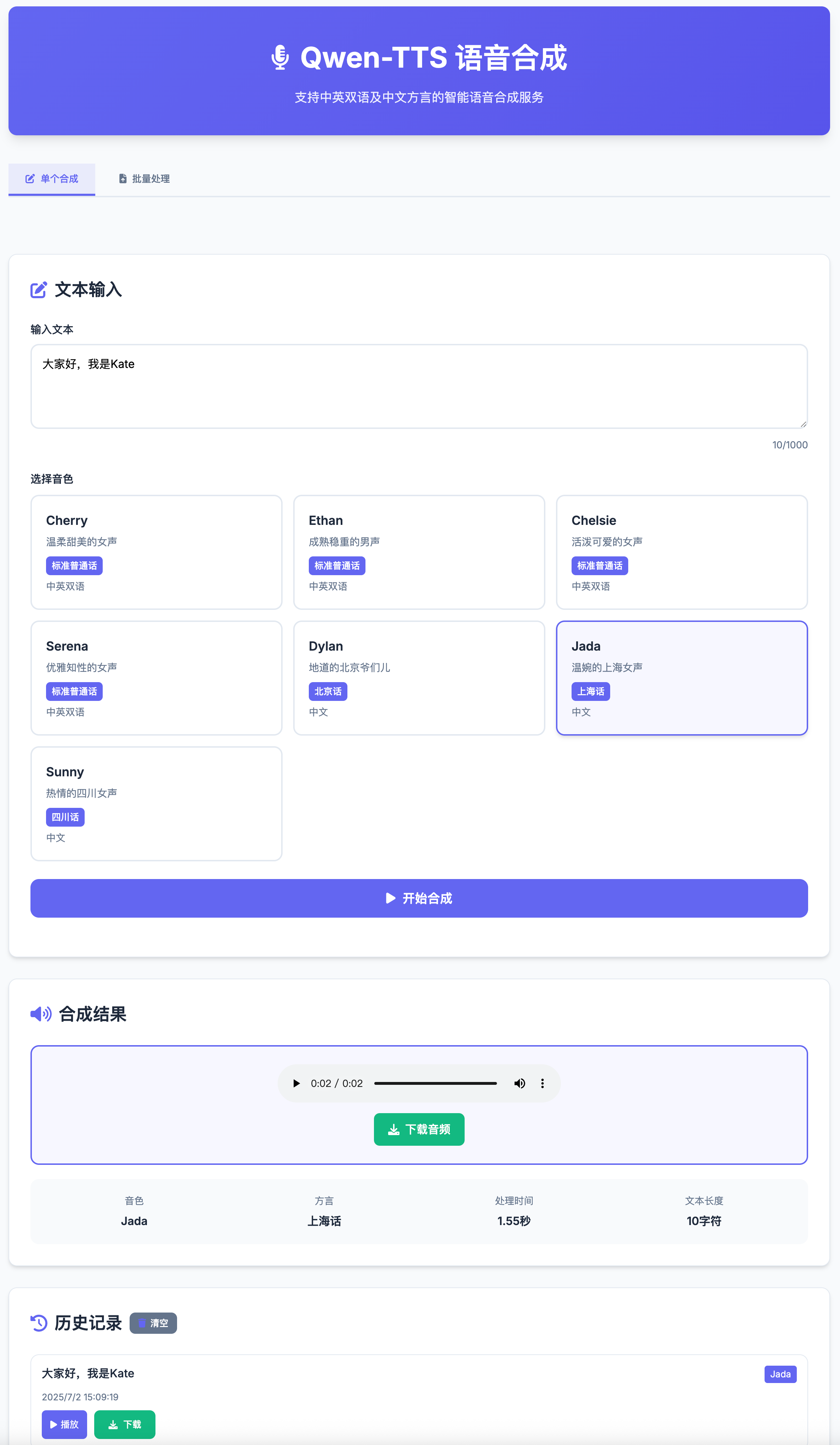
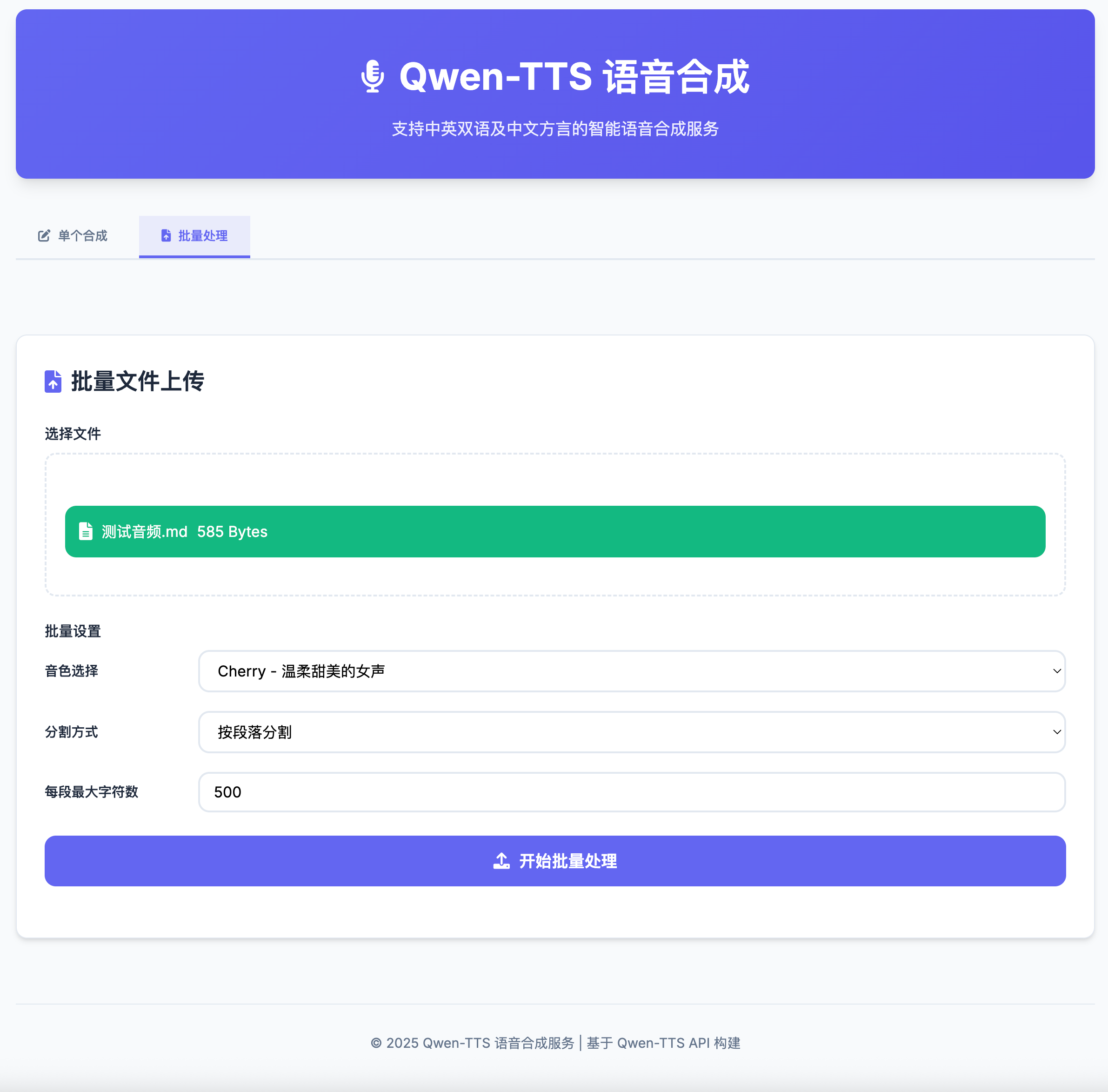
- 多音色支持: 7种不同音色,包括中英双语和方言
- 方言支持: 北京话、上海话、四川话
- 实时合成: 快速响应的语音合成
- 批量处理: 支持txt/md文件批量上传和处理
- 智能分割: 按段落、句子或章节自动分割文本
- 进度跟踪: 实时显示批量处理进度
- 音频播放: 在线播放和下载功能
- 音频格式: 默认输出 WAV 格式,音质清晰
- 现代化设计: 美观的响应式界面
- 一致性布局: 单个合成和批量处理页面宽度统一(1200px)
- 直观操作: 简单易用的用户体验
- 历史记录: 自动保存合成历史
- 实时反馈: 字符计数和状态提示
- 异步处理: 高性能的异步 API
- 错误处理: 完善的错误处理机制
- 文件管理: 自动音频文件管理
- API 文档: 完整的 OpenAPI 文档
| 音色 | 语言 | 描述 | 方言 |
|---|---|---|---|
| Cherry | 中英双语 | 温柔甜美的女声 | 标准普通话 |
| Ethan | 中英双语 | 成熟稳重的男声 | 标准普通话 |
| Chelsie | 中英双语 | 活泼可爱的女声 | 标准普通话 |
| Serena | 中英双语 | 优雅知性的女声 | 标准普通话 |
| Dylan | 中文 | 地道的北京爷们儿 | 北京话 |
| Jada | 中文 | 温婉的上海女声 | 上海话 |
| Sunny | 中文 | 热情的四川女声 | 四川话 |
# 克隆项目到本地
git clone https://github.com/nicekate/qwen-tts.git
# 进入项目目录
cd qwen-tts确保已安装 Python 3.8+ 并下载项目文件。
方式一:使用安装脚本(推荐)
# 运行自动安装脚本
python install.py方式二:手动安装
# 安装项目依赖
pip install -r requirements.txt
# 复制环境变量模板
cp .env.example .env依赖包说明:
- fastapi - Web 框架
- uvicorn - ASGI 服务器
- dashscope - 阿里云 DashScope SDK
- requests - HTTP 请求库
- python-multipart - 文件上传支持
- jinja2 - 模板引擎
- aiofiles - 异步文件操作
- pydantic - 数据验证
- python-dotenv - 环境变量管理
# 复制环境变量模板
cp .env.example .env
# 编辑 .env 文件,添加您的 DashScope API Key
# DASHSCOPE_API_KEY=sk-your_api_key_here获取 API Key 的步骤:
- 访问 阿里云百炼平台 API Key 管理页面
- 登录您的阿里云账号
- 在 "API-KEY管理" 页面创建新的 API Key
- 复制生成的 API Key(格式通常为
sk-xxxxxxxxxx) - 将 API Key 粘贴到项目根目录的
.env文件中
重要说明:
- API Key 必须是有效的 DashScope API Key
- 请确保您的账户有足够的余额或免费额度
- 请妥善保管您的 API Key,不要泄露给他人
# 使用启动脚本(推荐)
python start.py
# 或直接启动
python main.py
# 或使用 uvicorn
uvicorn main:app --host 0.0.0.0 --port 8000 --reload- Web 界面: http://localhost:8000
- API 文档: http://localhost:8000/docs
- ReDoc 文档: http://localhost:8000/redoc
# 运行演示脚本,测试所有音色
python demo.py演示脚本会自动测试不同音色的语音合成功能,包括:
- Cherry(温柔甜美的女声)
- Dylan(地道的北京爷们儿)
- Jada(温婉的上海女声)
- Ethan(成熟稳重的男声)
- 在"单个合成"标签页输入文本
- 选择音色
- 点击"开始合成"
- 播放或下载生成的音频
- 切换到"批量处理"标签页
- 上传txt或md文件(支持拖拽)
- 选择音色和分割方式:
- 按段落分割: 根据空行分割文本
- 按句子分割: 根据句号等标点分割
- 按章节分割: 根据标题标记分割
- 设置每段最大字符数(100-1000)
- 点击"开始批量处理"
- 实时查看处理进度
- 逐个播放或下载生成的音频
- 文件支持: .txt 和 .md 格式
- 智能分割: 多种分割方式适应不同文档结构
- 并发处理: 最多3个任务同时处理,提高效率
- 进度跟踪: 实时显示总数、完成数、失败数
- 错误处理: 单个段落失败不影响其他段落
- 文件命名:
batch_[任务ID]_[序号]_[音色]_[时间戳]_[随机ID].wav
curl -X POST "http://localhost:8000/api/synthesize" \
-H "Content-Type: application/json" \
-d '{
"text": "你好,这是一个测试",
"voice": "Cherry"
}'curl "http://localhost:8000/api/voices"curl "http://localhost:8000/api/health"| 参数 | 类型 | 范围 | 默认值 | 描述 |
|---|---|---|---|---|
| text | string | 1-1000字符 | - | 要合成的文本 |
| voice | string | 见音色列表 | Cherry | 音色选择 |
qwen-tts-test/
├── main.py # FastAPI 主应用
├── config.py # 配置文件
├── start.py # 启动脚本
├── requirements.txt # 依赖列表
├── .env.example # 环境变量模板
├── README.md # 项目说明
├── templates/ # HTML 模板
│ └── index.html # 主页模板
├── static/ # 静态资源
│ ├── style.css # 样式文件
│ └── script.js # JavaScript 脚本
└── audio_output/ # 音频输出目录
DASHSCOPE_API_KEY: DashScope API 密钥(必需)
在 config.py 中可以修改:
- 服务器端口和主机
- 音频输出目录
- 请求超时时间
- 支持的音色配置
-
API Key 错误
- 检查
.env文件是否存在 - 确认 API Key 是否正确设置
- 检查
-
音频播放失败
- 检查浏览器是否支持音频播放
- 确认音频文件是否正确生成
-
合成失败
- 检查网络连接
- 确认 API Key 是否有效
- 查看控制台错误信息
启动服务时会显示详细的日志信息,包括:
- API 调用状态
- 错误信息
- 性能指标
本项目基于 MIT 许可证开源。
- 界面优化: 将批量合成页面宽度调整为与单个合成页面一致(1200px),提供更统一的用户体验
- 性能优化: 优化页面加载速度和响应性能
如有问题,请查看: