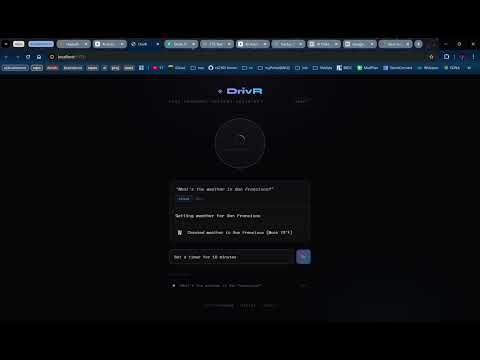
Built at the Cactus × Google DeepMind Hackathon, Singapore 2026. DrivR is a hands-free voice assistant for drivers that runs AI locally on-device using FunctionGemma + Cactus, with seamless fallback to Gemini for complex commands.

- Cactus runs Google DeepMind's FunctionGemma at up to 3000 toks/sec prefill speed on M4 Macs.
- While decode speed reaches 200 tokens/sec, all without GPU, to remain energy-efficient.
- FunctionGemma is great at tool calling, but small models are not the smartest for some tasks.
- There is a need to dynamically combine edge and cloud (Gemini Flash) to get the best of both worlds.
- Cactus develops various strategies for choosing when to fall back to Gemini or FunctionGemma.
- FunctionGemma is just a tool-call model, but tool calling is the core of agentic systems.
- You MUST design new strategies that decide when to stick with on-device or fall to cloud.
- You will be objectively ranked on tool-call correctness, speed and edge/cloud ratio (priortize local).
- You can focus on prompting, tool description patterns, confidence score algorithms, anything!
- Please ensure at least 1 team member has a Mac, Cactus runs on Macs, mobile devices and wearables.
- Step 1: Fork this repo, clone to your Mac, open terminal.
- Step 2:
git clone https://github.com/cactus-compute/cactus - Step 3:
cd cactus && source ./setup && cd ..(re-run in new terminal) - Step 4:
cactus build --python - Step 5:
cactus download google/functiongemma-270m-it --reconvert - Step 6: Get cactus key from the cactus website
- Sept 7: Run
cactus authand enter your token when prompted. - Step 8:
pip install google-genai - Step 9: Obtain Gemini API key from Google AI Studio
- Step 10:
export GEMINI_API_KEY="your-key" - Step 11: Click on location to get Gemini credits - SF, Boston, DC, London, Singapore, Online
- Step 12: Join the Reddit channel, ask any technical questions there.
- Step 13: read and run
python benchmark.pyto understand how objective scoring works. - Note: Final objective score will be done on held-out evals, top 10 are then judged subjectively.
- Your main task is to modify the internal logic of the
generate_hybridmethod inmain.py. - Do not modify the input or output signature (function arguments and return variables) of the
generate_hybridmethod. Keep the hybrid interface compatible withbenchmark.py. - Submit to the leaderboard
python submit.py --team "YourTeamName" --location "YourCity", only 1x every 1hr. - The dataset is a hidden Cactus eval, quite difficult for FunctionGemma by design.
- Use
python benchmark.pyto iterate, but your best score is preserved. - For transparency, hackers can see live rankings on the leaderboard.
- Leaderboard will start accepting submissions once event starts.
- The top 10 in each location will make it to judging.
- Rubric 1: The quality of your hybrid routing algorithm, depth and cleverness.
- Rubric 2: End-to-end products that execute function calls to solve real-world problems.
- Rubric 3: Building low-latency voice-to-action products, leveraging
cactus_transcribe.
import json
from cactus import cactus_init, cactus_complete, cactus_destroy
model = cactus_init("weights/lfm2-vl-450m")
messages = [{"role": "user", "content": "What is 2+2?"}]
response = json.loads(cactus_complete(model, messages))
print(response["response"])
cactus_destroy(model)| Parameter | Type | Description |
|---|---|---|
model_path |
str |
Path to model weights directory |
corpus_dir |
str |
(Optional) dir of txt/md files for auto-RAG |
model = cactus_init("weights/lfm2-vl-450m")
model = cactus_init("weights/lfm2-rag", corpus_dir="./documents")| Parameter | Type | Description |
|---|---|---|
model |
handle | Model handle from cactus_init |
messages |
list|str |
List of message dicts or JSON string |
tools |
list |
Optional tool definitions for function calling |
temperature |
float |
Sampling temperature |
top_p |
float |
Top-p sampling |
top_k |
int |
Top-k sampling |
max_tokens |
int |
Maximum tokens to generate |
stop_sequences |
list |
Stop sequences |
include_stop_sequences |
bool |
Include matched stop sequences in output (default: False) |
force_tools |
bool |
Constrain output to tool call format |
tool_rag_top_k |
int |
Select top-k relevant tools via Tool RAG (default: 2, 0 = use all tools) |
confidence_threshold |
float |
Minimum confidence for local generation (default: 0.7, triggers cloud_handoff when below) |
callback |
fn |
Streaming callback fn(token, token_id, user_data) |
# Basic completion
messages = [{"role": "user", "content": "Hello!"}]
response = cactus_complete(model, messages, max_tokens=100)
print(json.loads(response)["response"])# Completion with tools
tools = [{
"name": "get_weather",
"description": "Get weather for a location",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"]
}
}]
response = cactus_complete(model, messages, tools=tools)
cactus_complete(model, messages, callback=on_token)Response format (all fields always present):
{
"success": true,
"error": null,
"cloud_handoff": false,
"response": "Hello! How can I help?",
"function_calls": [],
"confidence": 0.85,
"time_to_first_token_ms": 45.2,
"total_time_ms": 163.7,
"prefill_tps": 619.5,
"decode_tps": 168.4,
"ram_usage_mb": 245.67,
"prefill_tokens": 28,
"decode_tokens": 50,
"total_tokens": 78
}Cloud handoff response (when model detects low confidence):
{
"success": false,
"error": null,
"cloud_handoff": true,
"response": null,
"function_calls": [],
"confidence": 0.18,
"time_to_first_token_ms": 45.2,
"total_time_ms": 45.2,
"prefill_tps": 619.5,
"decode_tps": 0.0,
"ram_usage_mb": 245.67,
"prefill_tokens": 28,
"decode_tokens": 0,
"total_tokens": 28
}-
When
cloud_handoffisTrue, the model's confidence dropped belowconfidence_threshold(default: 0.7) and recommends deferring to a cloud-based model for better results. -
You will NOT rely on this, hackers must design custom strategies to fall-back to cloud, that maximizes on-devices and correctness, while minimizing end-to-end latency!
| Parameter | Type | Description |
|---|---|---|
model |
handle | Whisper model handle |
audio_path |
str |
Path to audio file (WAV) |
prompt |
str |
Whisper prompt for language/task |
whisper = cactus_init("weights/whisper-small")
prompt = "<|startoftranscript|><|en|><|transcribe|><|notimestamps|>"
response = cactus_transcribe(whisper, "audio.wav", prompt=prompt)
print(json.loads(response)["response"])
cactus_destroy(whisper)| Parameter | Type | Description |
|---|---|---|
model |
handle | Model handle |
text |
str |
Text to embed |
normalize |
bool |
L2-normalize embeddings (default: False) |
embedding = cactus_embed(model, "Hello world")
print(f"Dimension: {len(embedding)}")Reset model state (clear KV cache). Call between unrelated conversations.
cactus_reset(model)Stop an ongoing generation (useful with streaming callbacks).
cactus_stop(model)Free model memory. Always call when done.
cactus_destroy(model)Get the last error message, or None if no error.
error = cactus_get_last_error()
if error:
print(f"Error: {error}")Query RAG corpus for relevant text chunks. Requires model initialized with corpus_dir.
| Parameter | Type | Description |
|---|---|---|
model |
handle | Model handle (must have corpus_dir set) |
query |
str |
Query text |
top_k |
int |
Number of chunks to retrieve (default: 5) |
model = cactus_init("weights/lfm2-rag", corpus_dir="./documents")
chunks = cactus_rag_query(model, "What is machine learning?", top_k=3)
for chunk in chunks:
print(f"Score: {chunk['score']:.2f} - {chunk['text'][:100]}...")- Join the Reddit channel, ask any technical questions there.
- To gain some technical insights on AI, checkout Maths, CS & AI Compendium.