This is the project for the course AIST2010 [Introduction to Computer Music]
Code for presentation / demonstration purpose:
1. demo1.py
- Search song metadata using Spotify API
- Client ID and Client Secret can be generated in https://developer.spotify.com/dashboard/login
2. demo2.py
- Extract the frequency value with the highest 2000 magnitude of a .wav file
3. demo3.py
- Extract spectral features of a .wav file
4. demo4.py
- Demonstrating probability curve of logistic regression
5. demo5.py
- Demonstrating decision making of decision tree classifier
6. demo6.py
- Demonstrating the network connection of neural network
7. demo7.py
- Extract the magnitude value of frequency from 0Hz to 11025Hz of a .wav file
Code for the whole project (including data preparation and model training):
notebook.ipynb
- Detailed explanation of the code is included in the notebook
- I also included notebook.pdf which includes the code and output of the above notebook
Code for classifying music genre using the trained model:
script.py
- You may either provide a .wav file, song name or YouTube URL to the program
- Please download the models from the Release page and put the files into the same directory with script.py
Remaining files:
1. logistic_regression.png
- probability curve generated by demo4.py
2. decision_tree.png
- decision graph generated by demo5.py
3. network.gv.pdf
- neural network graph generated by demo6.py
4. spectrum.png
- spectrum of the first audio file for each genre
5. spectrogram.png
- spectrogram of the first audio file for each genre
6. evaluate.ipynb
- evaluate model on the original dataset
Tested PC Environment:
Operating System: Windows 10 Home
Hardware: Intel i7-9750H, NVIDIA GTX 1660 TI
Tested Python Environment
Python version: 3.9.6
Library version:
- audiomentation==0.19.1
- tqdm==4.62.2
- tensorflow==2.5.0
- spotipy==2.19.0
- seaborn==0.11.2
- scipy==1.7.1
- scikit-learn==1.0
- pandas==1.3.3
- pedalboard==0.3.8
- numpy==1.20.3
- multiprocess==0.70.12.2
- matplotlib==3.4.2
- librosa==0.8.1
- youtube_dl==2021.6.6
It is common for everyone to search for music by typing in their favourite genre. However, with new songs being created every minute, it is somewhat subjective and time-consuming to listen to them one by one and then judge their genre.
Therefore, for my project, the aim was to create a generic model to classify music genres. Throughout the project, I tried to use four different approaches.
Initially, the plan was to prepare a dataset by downloading music from YouTube and using the Spotify API to extract song metadata. However, it soon became apparent to me that most of the songs in Spotify were missing content in the 'genre' field. I therefore decided to use the GTZAN dataset, which includes 10 music genres, each containing 100 audio files.
I also searched for references on Kaggle. They all attempted to extract spectral features from the audio files for model training. The main difference was simply the models they chose. The accuracy rates I saw on Kaggle were around 60% to 70%. In my four attempts, the data extraction was attempted by performing FFT and extracting the spectral features from the audio files.
Four approaches were tried in this project. The programming language I chose was Python. There were 10 types of music and in total 1000 audio files. For all attempts, 70% of the dataset was split into a training set and 30% into a test set.
After looking at the spectrogram and spectrum among all types of music, I think it would be possible to build a classifier using the frequencies with the highest magnitude. Therefore, I extracted 2000 frequencies by performing FFT on each audio file. The dataset is then frequencies ordered by its magnitude. Performance is shown as below:
| Training Accuracy | Testing Accuracy | |
|---|---|---|
| Logistic Regression | 100% | 12.6% |
| Random Forest Classifier | 100% | 35.6% |
| Simple Neural Network | 29.6% | 15.6% |
| Convolutional Neural Network | 100% | 17% |
No matter what model I have chosen, the testing accuracy is low. I also tried to increase and decrease the number of frequencies to be extracted in the audio files but there are only slight changes in the accuracy. Hence, this approach is in the wrong direction.
In my second attempt, I tried to extract spectral features as listed in the following:
- chroma stft mean
- chroma stft variance
- rms mean
- rms variance
- spectral centroid mean
- spectral centroid variance
- spectral bandwidth mean
- spectral bandwidth variance
- spectral rolloff mean
- spectral rolloff variance
- zero crossing rate mean
- zero crossing rate variance
- tempo
- Mel-frequency cepstral coefficients
This approach is adopted by most people for classifying music genre. Ideal accuracy is expected. For the calculation, I mainly use Librosa and NumPy. Since Librosa calculates the above spectral features (except tempo) by splitting the audio into several analysis frames, I calculate the mean and variance to estimate the overall value and the dispersion of the feature throughout the whole audio. Performance is shown as below:
| Training Accuracy | Testing Accuracy | |
|---|---|---|
| Logistic Regression | 47.6% | 44.6% |
| Random Forest Classifier | 99.8% | 68.6% |
| Simple Neural Network | 99.5% | 72.6% |
The accuracy in this attempt has much increased and the accuracy of the model is closed to the work of people on Kaggle.
During my research, I did not find anyone doing music genre classification by extracting data using FFT. In my third attempt, I tried to extract the magnitude among frequencies from 0 to 11025Hz by performing FFT. To reduce the complexity of the dataset, decimal points for the frequency value are ignored and the maximum magnitude is chosen among the “same” frequency. Hence, each audio file is represented by 11,026 features. Performance is shown as below:
| Training Accuracy | Testing Accuracy | |
|---|---|---|
| Logistic Regression | 100% | 54% |
| Random Forest Classifier | 100% | 55.6% |
| Simple Neural Network | 72.4% | 48.3% |
| Convolutional Neural Network | 93.3% | 53% |
The accuracy in this attempt has slightly decreased. However, it proved that extracting the magnitude of frequencies may be useful in classifying music genre. The performance may be enhanced if the dataset is larger.
In order to enhance the performance in the previous attempt, I tried making the dataset larger in my fourth attempt by using Pedalboard (a library opened sourced by Spotify recently), Librosa and Audiomentations. The following sound effects are used:
- Reverb / Chorus
- Distortion
- Pitch Shift
- Time Stretch
- Noise
The size of the dataset is then increased from 1000 to 81,000. The main idea is that the song is in the same genre no matter where it is performed and no matter the song is performed by a male or a female.
Since the dataset is large and contains 11,026 columns, I first tried to perform principal component analysis to reduce the dimensionality of the dataset from 11,026 to 2,000. However, the accuracy of training data and testing data is both only 10% which is totally unacceptable. Hence, instead of reducing dimensionality, I tried to standardize all features in the dataset (removing mean and scaling to unit variance). Then, I feed the data to a CNN model again and get almost 99% accuracy for training data and 98% accuracy for testing data. The confusion matrix for testing data is shown as followed:
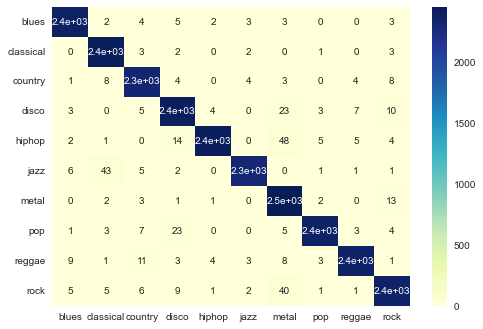
Remark: If the model is evaluated on the original dataset (rather than the enlarged dataset), only one sound file is classified incorrectly. The accuracy is 99.9%. (For details, please refer to evaluate.ipynb)
The trained model above was stored as a TFLite model "model2.tflite" and the standardization model was stored as "scaler.pkl". A script was also written to support the classification of music by providing a .wav file, a song name (the song would then be downloaded in YouTube and converted to a .wav file) or a YouTube URL. To evaluate the performance of the model, the following songs that never appeared in the dataset were fed into the model:
| Song Name | Predicted Genre |
|---|---|
| Beethoven - Für Elise | classical |
| Pachelbel - Canon In D Major | classical |
| Luis Fonsi – Despacito ft. Daddy Yankee | pop |
| The Chainsmokers – Don’t Let Me Down | pop |
| Wiz Khalifa – See You Again ft. Charlie Puth | reggae |
I have tried several songs and many of them are classified correctly. Hence, through having a larger dataset, the accuracy can be increased significantly, and the data extracted by performing FFT is then proved to be valuable in music genre classification.
Simple Demo:
With the limitations of the hardware I have, a more complex model cannot be built as there is not enough memory and the computation time is too long. Because of the time constraints, only the GTZAN dataset was used to train my model. Therefore, if a song given to the model is not in English, the performance may decay a lot. In addition, only ten types of music are available to my model, which is not general enough. Last but not least, due to the lack of knowledge in Tensorflow, the definition of the model could have been written more elegantly.
Throughout the project, I experimented with a variety of Python libraries that I was unfamiliar with before taking this course, and looked closely at machine learning. Having experimented with the methods most people use for music genre classification, I also discovered some completely new ideas myself. Surprisingly, by making a larger dataset and preparing the data by performing FFT, it was already possible to achieve a very high accuracy rate. Therefore, the project will continue to be improved in the future by introducing more genres and obtaining a larger dataset.
[1] Spotify, “Pedalboard”, GitHub, 2021. [Source code]. Available: https://github.com/spotify/pedalboard. [Accessed: 2021].
[2] iver56, “Audiomentations”, GitHub, 2021. [Online]. Available: https://github.com/iver56/audiomentations. [Accessed: 2021].
[3] Christianlomboy, “Mir-genre-predictor,” GitHub, 2020. [Online]. Available: https://github.com/christianlomboy/MIR-Genre-Predictor. [Accessed: 2021].
[4] E. Klyshko, “Signal Processing in Python”, 22-Feb-2019. [Online]. Available: https://klyshko.github.io/teaching/2019-02-22-teaching. [Accessed: 2021].
[5] A. Chowdhry, “Music genre classification using CNN”, Medium, 07-May-2021. [Online]. Available: https://blog.clairvoyantsoft.com/music-genre-classification-using-cnn-ef9461553726. [Accessed: 2021].
[6] L. P. Coelho, W. Richert, and M. Brucher, Building Machine Learning Systems with python. Birmingham, UK: Packt Publishing, 2018.
[7] T. Holdroyd, TensorFlow 2.0 Quick Start Guide. Birmingham, UK: Packt Publishing, 2019.
[8] A. Olteanu, “GTZAN dataset - music genre classification,” Kaggle, 24-Mar-2020. [Online]. Available: https://www.kaggle.com/andradaolteanu/gtzan-dataset-music-genre-classification. [Accessed: 2021].