Semantic segmentation is the process of classifying each pixel in an image belonging to the class it belongs to. It differs from Instance Segmentation as it does not count on instances of the same class occurring in a given image. It outputs the same label to all the pixels of the same class objects.
It's been extensively used in self-driving cars. For a car to move independently, it should understand its surroundings completely at the pixel level. In this project, I have used semantic segmentation to identify the movement of other vehicles and pedestrians in the given video frame or image. The most common classes could be pedestrians, cars, trucks, trees (vegetation), sky, buildings and the list goes on.
The dataset used here is popular and one of the first released datasets for semantic segmentation tasks with labels. The images are extracted from the video sequence recorded for 10 minutes. The camera was set up on the dashboard of the car, with a view close to that of the driver.
The dataset can be downloaded from the Kaggle website https://www.kaggle.com/carlolepelaars/camvid.
The dataset is divided as:
Training data pairs - 367
Validation data pairs - 101
Test data pairs - 223
The same split ratio for the CamVid semantic segmentation was used in many research papers.
-
Data-preprocessing
-
Data-loading (using custom dataloaders)
-
Developing the deep learning architecture
-
Training the model
-
Evaluating the model:
i. Pixel Accuracy
ii. Intersection over Union
-
Testing for a particular sample image
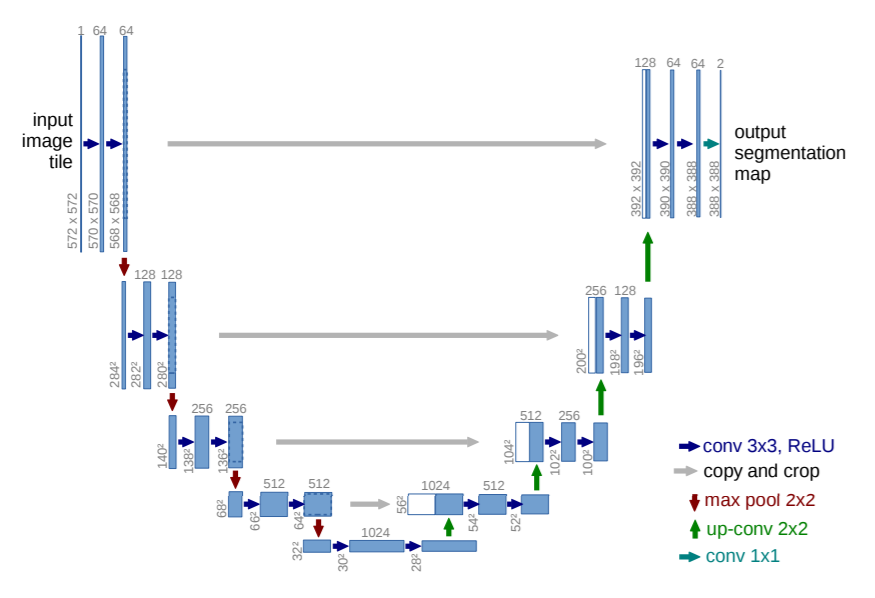
The advantage of U-Net architecture is it was built on fully convolutionaö network. It was primarily developed for semantic segmentation of medical tumours in lungs. The network is made of 2 sub parts. The first subpart is called encoder whose main task is to down-sample the input image to a feature map. The feature map is last layer is also called as latent space. From latent space the decoder network upsamples the image to the full size of the input image. The number of channels in the output image equals to number of classes we are classifying the image into. In this particular task, the total number of classes are 32. The spatial dimensions of the image are 256 in height and 256 in width.
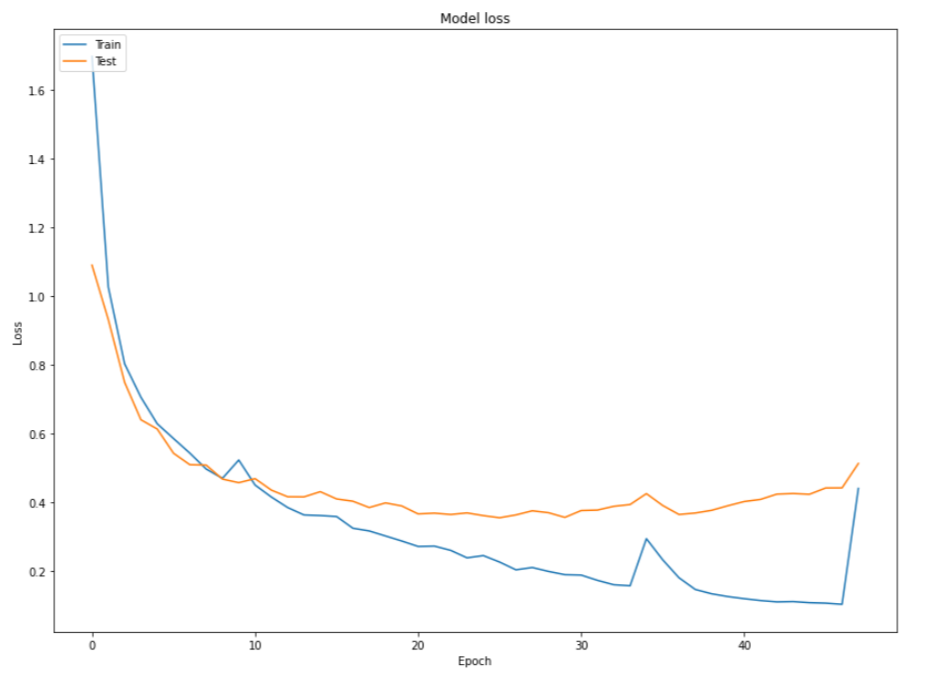
The configurations used for model training are as follows:
Batch Size = 8
Epochs = 100
Metrics - Intersection Over Union, accuracy
Loss - categorical crossentropy
A video named output_prediction1 is made with the images converted as video frames and uploaded in the repository.