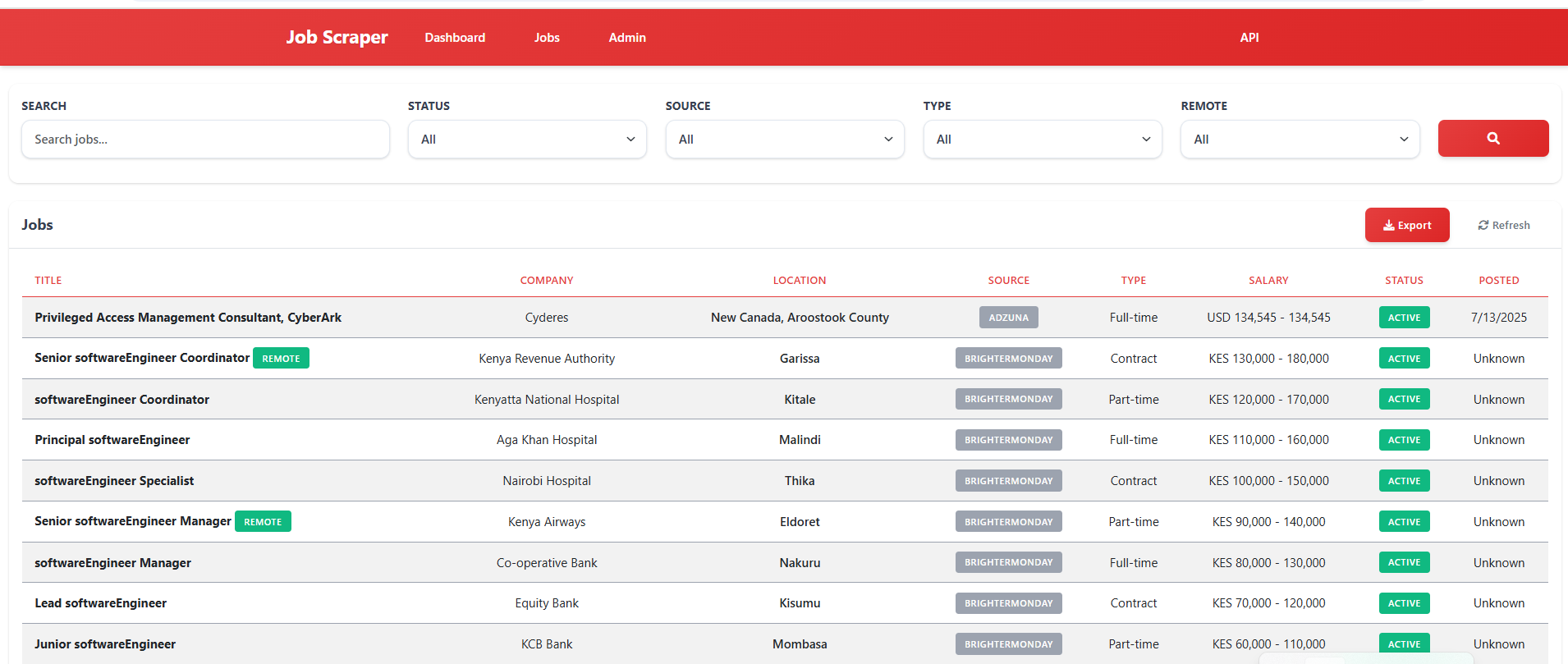
A comprehensive multi-platform job aggregator that scrapes job listings from various job sites including LinkedIn, Glassdoor, Indeed, RemoteOK, BrighterMonday, Fuzu, and Jobright. Built with Django, Selenium, and Docker for production deployment with a modern Kenya Airways-inspired red and white theme.
- Features
- Tech Stack
- Project Structure
- Quick Start
- Configuration
- API Documentation
- Job Sources
- Development
- Deployment
- Troubleshooting
- Contributing
- License
- Multi-platform job scraping from LinkedIn, Glassdoor, Indeed, RemoteOK, BrighterMonday, Fuzu, and Jobright
- Real-time job search with instant results
- API integration with Adzuna and custom Kenya Jobs API
- Duplicate job detection and intelligent merging
- Advanced filtering by location, company, salary, and job type
- CSV/Excel export functionality for job data
- RESTful API for data consumption and integration
- Modern dashboard with Kenya Airways-inspired red and white theme
- Responsive design that works on desktop and mobile
- Real-time search results with loading indicators
- Interactive job listings with detailed information
- Admin panel for system management
- Statistics overview with job counts and metrics
- Asynchronous task processing with Celery and Redis
- Docker containerization for easy deployment
- Anti-detection measures for reliable scraping
- Comprehensive logging and error handling
- Database optimization with proper indexing
- Caching strategies for improved performance
- Django 4.2.7 - Web framework
- Django REST Framework - API development
- PostgreSQL - Primary database (production)
- SQLite - Development database
- Celery - Asynchronous task queue
- Redis - Message broker and caching
- Selenium - Web browser automation
- BeautifulSoup - HTML parsing
- requests - HTTP client for API calls
- Chrome WebDriver - Browser automation engine
- Django Templates - Server-side rendering
- Bootstrap 5.3.0 - CSS framework
- jQuery - JavaScript library
- Font Awesome - Icon library
- Custom CSS - Kenya Airways theme
- Docker - Containerization
- Docker Compose - Multi-container orchestration
- Nginx - Web server (production)
- Gunicorn - WSGI server
job-scraper-dashboard/
├── backend/ # Django backend application
│ ├── apps/ # Django applications
│ │ ├── jobs/ # Job management and search
│ │ │ ├── management/commands/ # Custom management commands
│ │ │ ├── migrations/ # Database migrations
│ │ │ ├── models.py # Job and search models
│ │ │ ├── serializers.py # API serializers
│ │ │ ├── views.py # API and web views
│ │ │ ├── urls.py # URL routing
│ │ │ ├── filters.py # Query filtering
│ │ │ └── admin.py # Admin interface
│ │ ├── companies/ # Company management
│ │ │ ├── migrations/ # Database migrations
│ │ │ ├── models.py # Company models
│ │ │ ├── serializers.py # API serializers
│ │ │ ├── views.py # API views
│ │ │ ├── urls.py # URL routing
│ │ │ ├── filters.py # Query filtering
│ │ │ └── admin.py # Admin interface
│ │ └── scraping/ # Web scraping engine
│ │ ├── api_clients/ # External API integrations
│ │ │ ├── adzuna.py # Adzuna API client
│ │ │ ├── jobright.py # Jobright API client
│ │ │ └── kenya_jobs.py # Custom Kenya Jobs API
│ │ ├── scrapers/ # Web scrapers
│ │ │ ├── base.py # Base scraper class
│ │ │ ├── indeed.py # Indeed scraper
│ │ │ ├── glassdoor.py # Glassdoor scraper
│ │ │ ├── linkedin.py # LinkedIn scraper
│ │ │ ├── remoteok.py # RemoteOK scraper
│ │ │ ├── brightermonday.py # BrighterMonday scraper
│ │ │ └── fuzu.py # Fuzu scraper
│ │ ├── management/commands/ # Custom management commands
│ │ ├── migrations/ # Database migrations
│ │ ├── models.py # Scraping models
│ │ ├── tasks.py # Celery tasks
│ │ ├── views.py # API views
│ │ ├── urls.py # URL routing
│ │ ├── serializers.py # API serializers
│ │ ├── utils.py # Utility functions
│ │ └── admin.py # Admin interface
│ ├── config/ # Django configuration
│ │ ├── settings/ # Environment-specific settings
│ │ │ ├── base.py # Base settings
│ │ │ ├── development.py # Development settings
│ │ │ └── production.py # Production settings
│ │ ├── urls.py # Main URL configuration
│ │ ├── wsgi.py # WSGI configuration
│ │ ├── asgi.py # ASGI configuration
│ │ └── celery.py # Celery configuration
│ ├── requirements/ # Python dependencies
│ │ ├── base.txt # Base requirements
│ │ ├── dev.txt # Development requirements
│ │ └── prod.txt # Production requirements
│ └── manage.py # Django management script
├── frontend/ # Frontend assets and templates
│ ├── static/ # Static files
│ │ ├── css/ # Stylesheets
│ │ │ └── main.css # Main stylesheet with Kenya Airways theme
│ │ └── js/ # JavaScript files
│ │ └── main.js # Main JavaScript file
│ └── templates/ # Django templates
│ ├── base.html # Base template
│ ├── jobs/ # Job-related templates
│ │ ├── dashboard.html # Main dashboard
│ │ └── job_list.html # Job listings page
│ └── django_filters/ # Filter templates
│ └── rest_framework/
│ └── form.html # Filter form template
├── scripts/ # Utility scripts
│ ├── docker-logs.sh # Docker logs script (Linux/Mac)
│ ├── docker-logs.ps1 # Docker logs script (Windows)
│ └── setup.sh # Setup script
├── docker-compose.yml # Docker Compose configuration
├── Dockerfile # Docker image definition
├── env.example # Environment variables example
└── README.md # This file
- Docker and Docker Compose
- Git
- Modern web browser
-
Clone the repository
git clone <repository-url> cd job-scraper-dashboard
-
Set up environment variables
cp env.example .env # Edit .env with your configuration -
Build and run with Docker
docker-compose up --build
-
Access the application
- Dashboard: http://localhost:8000
- API: http://localhost:8000/api/
- Admin: http://localhost:8000/admin/
Recommended Platforms:
- Railway (Best for this project) - Deploy Guide
- DigitalOcean App Platform - Deploy Guide
- Heroku - Deploy Guide
Not Suitable:
- ❌ Vercel (No persistent database, 10s timeout limit)
- ❌ Firebase (No Python runtime, no Selenium support)
-
Create a superuser account
docker-compose exec web python manage.py createsuperuser -
Initialize job sources
docker-compose exec web python manage.py init_sources -
Run initial migrations
docker-compose exec web python manage.py migrate
Create a .env file in the root directory with the following variables:
# Django Settings
DEBUG=True
SECRET_KEY=your-secret-key-here
ALLOWED_HOSTS=localhost,127.0.0.1
# Database
DATABASE_URL=postgresql://user:password@db:5432/jobscraper
# Redis
REDIS_URL=redis://redis:6379/0
# API Keys
ADZUNA_APP_ID=your-adzuna-app-id
ADZUNA_APP_KEY=your-adzuna-app-key
# Scraping Settings
CHROME_HEADLESS=True
SCRAPING_DELAY=2
MAX_CONCURRENT_SCRAPERS=3The system supports multiple job sources:
- Indeed - Global job search
- Glassdoor - Company reviews and jobs
- LinkedIn - Professional network jobs
- RemoteOK - Remote job opportunities
- BrighterMonday - Kenya job market
- Fuzu - East Africa job platform
- Jobright - AI-powered job matching
- Adzuna - Job search API
http://localhost:8000/api/
Currently uses AllowAny permissions. For production, implement proper authentication.
GET /api/jobs/- List all jobsGET /api/jobs/{id}/- Get specific jobGET /api/jobs/statistics/- Get job statisticsGET /api/jobs/export/- Export jobs to CSV
GET /api/companies/- List all companiesGET /api/companies/{id}/- Get specific companyGET /api/companies/statistics/- Get company statistics
GET /api/sessions/- List scraping sessionsGET /api/sessions/{id}/- Get specific sessionPOST /api/sessions/{id}/execute/- Execute scraping session
GET /api/sources/- List job sourcesGET /api/sources/{id}/- Get specific source
import requests
# Get all jobs
response = requests.get('http://localhost:8000/api/jobs/')
jobs = response.json()
# Search jobs with filters
params = {
'search': 'python developer',
'location': 'Nairobi',
'employment_type': 'Full-time'
}
response = requests.get('http://localhost:8000/api/jobs/', params=params)
filtered_jobs = response.json()
# Export jobs to CSV
response = requests.get('http://localhost:8000/api/jobs/export/')
with open('jobs.csv', 'wb') as f:
f.write(response.content)-
Indeed - Global job search engine
- Countries: US, UK, Canada, Australia, Kenya
- Features: Salary information, company details, location filtering
-
Glassdoor - Company reviews and job listings
- Features: Company ratings, salary insights, interview reviews
-
LinkedIn - Professional network job board
- Features: Professional networking, company connections
-
RemoteOK - Remote job opportunities
- Features: Remote work focus, global opportunities
-
BrighterMonday - Kenya job market
- Features: Local Kenyan jobs, company profiles
-
Fuzu - East Africa job platform
- Features: Regional focus, career development
-
Jobright - AI-powered job matching
- Features: Smart matching, personalized recommendations
-
Adzuna - Job search API
- Features: Real-time data, comprehensive coverage
- Anti-detection measures: Random user agents, delays, stealth mode
- Rate limiting: Respectful scraping with delays
- Error handling: Comprehensive logging and retry mechanisms
- Data validation: Clean and normalize scraped data
- Duplicate detection: Intelligent merging of similar jobs
-
Install Python dependencies
pip install -r backend/requirements/dev.txt
-
Set up database
python backend/manage.py migrate python backend/manage.py createsuperuser
-
Run development server
python backend/manage.py runserver
-
Run Celery worker (in separate terminal)
celery -A backend.config worker --loglevel=info
-
Run Celery beat (in separate terminal)
celery -A backend.config beat --loglevel=info
python backend/manage.py test- Linting: Use flake8 or black for code formatting
- Type hints: Add type annotations for better code clarity
- Documentation: Follow Django documentation standards
- Testing: Write unit tests for new features
- Create scraper class in
backend/apps/scraping/scrapers/ - Inherit from BaseScraper and implement required methods
- Add to scrapers dictionary in
tasks.py - Update models if new fields are needed
- Add tests for the new scraper
Example:
# backend/apps/scraping/scrapers/new_source.py
from .base import BaseScraper
class NewSourceScraper(BaseScraper):
def __init__(self):
super().__init__()
self.base_url = "https://example.com"
def scrape_jobs(self, query, location=None, max_results=50):
# Implement scraping logic
pass-
Set up production environment
cp env.example .env.production # Configure production settings -
Build production image
docker-compose -f docker-compose.prod.yml build
-
Deploy with Docker Compose
docker-compose -f docker-compose.prod.yml up -d
- Development: Debug enabled, SQLite database, local Redis
- Production: Debug disabled, PostgreSQL database, Redis cluster
- Testing: In-memory database, mock external services
- Application logs: Available via Docker logs
- Error tracking: Implement Sentry or similar service
- Performance monitoring: Use Django Debug Toolbar in development
- Health checks: Implement health check endpoints
-
Docker build fails
- Check Docker and Docker Compose versions
- Ensure sufficient disk space
- Verify network connectivity
-
Database connection errors
- Check database service status
- Verify connection credentials
- Ensure database is accessible
-
Scraping fails
- Check internet connectivity
- Verify target websites are accessible
- Review anti-detection measures
- Check Chrome WebDriver installation
-
Static files not loading
- Run
python manage.py collectstatic - Check static file configuration
- Verify web server configuration
- Run
-
View application logs
docker-compose logs -f web
-
Access container shell
docker-compose exec web bash -
Check database
docker-compose exec web python manage.py dbshell -
Run management commands
docker-compose exec web python manage.py <command>
-
Database optimization
- Add proper indexes
- Use database connection pooling
- Implement query optimization
-
Caching strategies
- Redis caching for frequently accessed data
- Template fragment caching
- API response caching
-
Scraping optimization
- Implement concurrent scraping
- Use headless browser mode
- Optimize selectors and parsing
- Fork the repository
- Create a feature branch
- Make your changes
- Add tests for new features
- Ensure all tests pass
- Submit a pull request
- Follow PEP 8 for Python code
- Use meaningful variable and function names
- Add docstrings for functions and classes
- Write comprehensive tests
- Update documentation for new features
- Provide clear description of changes
- Include screenshots for UI changes
- Ensure all tests pass
- Update documentation as needed
- Follow the existing code style
This project is licensed under the MIT License - see the LICENSE file for details.
For support and questions:
- Create an issue in the GitHub repository
- Check the troubleshooting section
- Review the API documentation
- Contact the development team
- Initial release with multi-platform job scraping
- Kenya Airways-inspired theme
- Docker containerization
- REST API implementation
- Admin dashboard
- CSV export functionality
Built with Django, Selenium, and Docker for reliable job scraping and management.