A dynamic, AI-powered Bluesky custom feed generation platform. Create, publish, and manage any number of topic-based feeds directly from a web admin panel — no code changes required. Built on the AT Protocol firehose, NLP sentence embeddings, GPT-4o seed generation, and Vue.js — deployed on Railway.
Live admin panel: https://web-production-77bc8f.up.railway.app/admin
📖 Documentation & Demo: osmankantarcioglu.github.io/BlueSky
- Overview
- Architecture
- How a New Feed Gets Created
- Project Structure
- Components
- NLP Pipeline
- Feed Ranking
- Admin Panel
- Deployment
- Environment Variables
- Database Schema
- Troubleshooting
BlueSky Feed Studio lets you create custom Bluesky feeds for any topic without touching code. The platform:
- Generates seed data with AI — enter a topic, GPT-4o produces 100+ keywords and 50+ social-media-style sentences
- Builds NLP centroids automatically — the worker computes a 768-dim embedding centroid from the seed sentences
- Publishes to Bluesky via AT Protocol — the feed is registered under your account with one click
- Filters the firehose in real time — posts are classified by cosine similarity to the feed's centroid
- Hot-reloads without restart — the worker polls the database every 60 seconds and picks up new feeds automatically
Two feeds bootstrapped automatically on first worker startup:
| Feed | Rkey | Language | Description |
|---|---|---|---|
| Türkiye Siyaset | turkiye-siyaset |
Turkish | Turkish political posts — parliament, parties, elections |
| Türkiye Bilim | turkiye-bilim |
Turkish | Turkish science — research, academia, publications |
┌──────────────────────────────────────────────────────────────┐
│ Admin Panel (/admin) │
│ Vue 3 + Glassmorphism UI │
│ │
│ 1. Enter topic → GPT-4o generates keywords + sentences │
│ 2. Review → submit form │
│ 3. Feed saved to DB → published to Bluesky (AT Protocol) │
└──────────────────────────────┬───────────────────────────────┘
│ PostgreSQL
▼
┌──────────────────────────────────────────────────────────────┐
│ feeds table (one row per feed) │
│ id │ feed_id │ keywords (JSON) │ centroid (JSON) │ at_uri │
└──────────────────────────────┬───────────────────────────────┘
│
┌────────────────┴─────────────────┐
│ │
▼ ▼
┌─────────────────────────┐ ┌───────────────────────────┐
│ Flask Feed Server │ │ NLP Worker (firehose) │
│ (Railway web) │ │ (Railway BlueSky) │
│ │ │ │
│ AT Protocol endpoints │ │ ① Poll DB every 60s │
│ /admin (Vue.js UI) │ │ ② Build missing centroids│
│ Dynamic feed routing │ │ ③ Subscribe to firehose │
│ by Feed.at_uri │ │ ④ Keyword pre-filter │
└─────────────────────────┘ │ ⑤ Cosine similarity │
│ ⑥ Save matched posts │
└───────────────────────────┘
│
▼
AT Protocol Firehose
wss://bsky.network (~300 events/sec)
User fills form in Admin Panel
│
▼
POST /admin/feeds/generate
GPT-4o generates:
├── 100+ keywords (used for fast pre-filter)
└── 50+ seed sentences (used to build centroid)
│
▼
POST /admin/feeds
├── Save Feed record to DB (keywords + sentences as JSON)
├── Build centroid:
│ embed_batch(seed_sentences) → mean → normalize → store as JSON
├── Publish to Bluesky:
│ atproto.client.put_record(app.bsky.feed.generator, rkey)
│ → returns AT URI → saved to Feed.at_uri
└── Feed.is_active = True
│
▼
Worker polls DB (next 60s cycle)
├── Detects new/changed feed
├── Rebuilds keyword_index {keyword → {feed_ids}}
└── Loads new FeedClassifier with centroid
│
▼
Firehose posts now matched against the new feed
BlueSky/
│
├── admin/ # Admin panel blueprint
│ ├── __init__.py
│ ├── routes.py # Flask Blueprint — all /admin/* routes
│ ├── services.py # Feed creation business logic
│ └── templates/
│ ├── layout.html # Base layout: animated blobs, glass sidebar, Vue CDN
│ ├── dashboard.html # Feed grid with stop/start/delete actions
│ ├── feed_new.html # 2-step wizard: AI generate → configure
│ └── feed_detail.html # Keyword cloud, seed sentences, recent posts
│
├── config/
│ └── settings.py # All constants + env variable loading
│
├── database/
│ └── models.py # Peewee ORM: Feed, Post, TrackedUser, LikeEvent, FeedSeedUser
│
├── data_collection/
│ ├── firehose_listener.py # AT Protocol firehose subscriber + multi-feed routing
│ └── seed_discovery.py # Load seed users from Excel → TrackedUser table
│
├── feed_generator/
│ ├── server.py # Flask server: AT Protocol endpoints + admin registration
│ └── feed_logic.py # Feed ranking algorithm (NLP score + engagement + recency)
│
├── nlp/
│ ├── embedder.py # TurkishEmbedder: BERTurk sentence embeddings (768-dim)
│ ├── model_manager.py # Singleton cache for embedding models by type
│ ├── domain_classifier.py # DomainClassifier (legacy) + FeedClassifier (dynamic)
│ ├── stance_detector.py # Alliance vs Opposition stance detection (TR politics)
│ └── pipeline.py # NLPPipeline (legacy) + MultiPipeline (multi-feed)
│
├── services/
│ └── llm_seed_generator.py # GPT-4o / Claude seed generation for any topic
│
├── scripts/
│ ├── publish_feed.py # CLI: register a feed on Bluesky
│ └── build_domain_centroids.py # CLI: pre-compute default centroids
│
├── Dockerfile.worker # Railway worker image (CPU torch + NLP deps)
├── Procfile # Railway web start command (waitress)
├── requirements.txt # Web server deps (no torch)
├── requirements-nlp.txt # Worker deps (torch + sentence-transformers)
├── runtime.txt # Python 3.11
└── .env.example # Environment variable template
Five Peewee ORM models. Automatic DB switch: DATABASE_URL → PostgreSQL (Railway), else SQLite (local dev).
Feed — one row per topic feed:
| Column | Type | Description |
|---|---|---|
id |
AutoField PK | Internal ID |
feed_id |
CharField unique | URL-safe slug, ≤ 15 chars (Bluesky rkey limit) |
display_name |
CharField | Human-readable name shown on Bluesky |
description |
TextField | Feed description |
language |
CharField | tr / en / multi |
topic |
CharField | Original topic entered by user |
at_uri |
CharField | AT URI after Bluesky registration |
keywords |
TextField | JSON list — used for firehose pre-filter |
seed_sentences |
TextField | JSON list — used to build centroid |
centroid |
TextField | JSON float list — 768-dim normalized vector |
embedding_model |
CharField | berturk / minilm / multilingual |
similarity_threshold |
FloatField | Min cosine similarity to accept a post |
is_active |
BooleanField | Whether worker listens for this feed |
updated_at |
DateTimeField | Touched on any change — triggers worker reload |
Post — every firehose post that matched a feed:
| Column | Type | Description |
|---|---|---|
uri |
CharField PK | AT URI of the post |
feed |
ForeignKeyField | Which feed this post belongs to |
domain_label |
CharField | Legacy: politics / science |
domain_score |
FloatField | Cosine similarity to feed centroid |
embedding |
TextField | JSON-encoded 768-dim vector |
feed_score |
FloatField | Combined ranking score (indexed) |
like_count / repost_count / reply_count |
IntegerField | Engagement |
TrackedUser — seed users whose posts are always forwarded to the NLP pipeline regardless of keyword match.
FeedSeedUser — per-feed seed user lists (many-to-many, for future per-feed user targeting).
LikeEvent — like events from the firehose (for engagement score updates).
Calls GPT-4o (or Claude as fallback) to generate seed data for any topic.
from services.llm_seed_generator import generate_seeds
data = generate_seeds(topic="FIFA World Cup 2026", language="en")
# data = {
# "keywords": ["fifa", "world cup", "mbappe", ...], # 100+ items
# "seed_sentences": ["Can't wait for the #WorldCup2026!", ...] # 50+ items
# }The prompt instructs the model to produce social-media-style sentences (short, hashtags, mentions) because centroid accuracy depends on seed sentences resembling real posts.
Thread-safe singleton that loads and caches embedding models. Prevents loading the same 400 MB checkpoint multiple times when multiple feeds share a model type.
from nlp.model_manager import ModelManager
embedder = ModelManager.get_embedder("berturk") # BERTurk 768-dim (Turkish)
embedder = ModelManager.get_embedder("minilm") # all-MiniLM-L6-v2 384-dim (English)
embedder = ModelManager.get_embedder("multilingual") # paraphrase-multilingual-MiniLM-L12-v2The core of the multi-feed classification system.
Startup:
MultiPipeline.load()
├── Query all active Feed records from DB
├── Build keyword_index: {keyword → {feed_id, ...}}
├── Load embedder per model_type (via ModelManager)
├── Build FeedClassifier per feed (centroid loaded from DB)
└── Auto-build centroid for feeds where centroid IS NULL
Per-post processing:
process_post(uri, text, ...)
├── ① get_candidate_feed_ids(text)
│ → O(K) scan of keyword_index, returns {feed_ids}
├── ② For each candidate feed:
│ ├── Language check (tr / en / multi)
│ └── cosine_similarity(embed(text), feed.centroid)
│ → score ≥ feed.similarity_threshold → candidate
└── ③ Save post to DB linked to highest-scoring feed
Hot reload (every 60 s):
MultiPipeline.reload()
├── Query feeds WHERE updated_at > last_reload
├── If any changed → _do_reload()
└── Keyword index and classifiers rebuilt atomically
Connects to wss://bsky.network/xrpc/com.atproto.sync.subscribeRepos.
Filter chain (fast → slow):
- Event type ==
app.bsky.feed.post(drops likes, follows, etc.) - Author DID in
seed_didsset OR text contains any feed keyword (O(1)/O(K)) - Push to
deque(maxlen=1000)queue - Background thread drains queue in batches of 32 →
MultiPipeline.process_post()
Three background threads:
_process_queue_worker— NLP processing every 5 s_reload_worker— polls DB for new/changed feeds every 60 s_stats_reporter— prints throughput every 60 s
Bootstrap on first run:
If no feeds exist in DB, creates turkiye-siyaset and turkiye-bilim using hardcoded keywords from config/settings.py and seed sentences from DomainClassifier.get_politics_sentences() / get_science_sentences().
Flask app implementing AT Protocol feed generator endpoints.
| Endpoint | Description |
|---|---|
GET /.well-known/did.json |
DID document for feed identity |
GET /xrpc/app.bsky.feed.describeFeedGenerator |
Lists all feeds with at_uri IS NOT NULL from DB |
GET /xrpc/app.bsky.feed.getFeedSkeleton?feed=<uri> |
Returns ranked post URIs for the given feed |
GET /health |
Status: {status, total_posts, active_feeds} |
GET /admin/* |
Admin panel (Vue.js UI) |
Feed routing is dynamic — getFeedSkeleton looks up the feed by Feed.at_uri in the database. No hardcoded feed URIs.
Feed score formula:
feed_score = (domain_score × 0.5 + log1p(engagement)/10 × 0.3) × recency_boost
recency_boost = max(0.5, 1.0 − age_hours/96)
→ 0 h old: 1.0
→ 24 h old: 0.75
→ 48+ h old: 0.5
get_posts_for_feed(feed_id) falls back to legacy domain_label for posts collected before the dynamic feed migration.
| Model type | HuggingFace repo | Dim | Best for |
|---|---|---|---|
berturk |
emrecan/bert-base-turkish-cased-mean-nli-stsb-tr |
768 | Turkish feeds |
minilm |
sentence-transformers/all-MiniLM-L6-v2 |
384 | English feeds |
multilingual |
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 |
384 | Mixed-language feeds |
Each feed has one centroid — the normalized mean embedding of its seed sentences. A post is accepted if:
cosine_similarity(embed(post_text), feed.centroid) ≥ feed.similarity_threshold
Default threshold: 0.30. The optimal value depends on the topic — niche technical topics may need a lower threshold.
Uses langdetect. Language check is per-feed:
language = 'tr'→ require Turkishlanguage = 'en'→ require Englishlanguage = 'multi'→ accept any language
| Factor | Weight | Notes |
|---|---|---|
| NLP similarity score | 50% | Topical relevance |
| Engagement (likes, reposts, replies) | 30% | Log-scaled to avoid viral dominance |
| Recency | Multiplier | Decays linearly over 48 h |
Scores are recomputed live on each getFeedSkeleton request to reflect current engagement.
URL: /admin
Built with Vue 3 (CDN, no build step) and custom glassmorphism CSS. Jinja2 renders server data; Vue handles interactivity with [[ ]] delimiters to avoid template conflicts.
Dashboard (/admin/)
- Stats bar: total feeds, active feeds, total posts
- Feed cards: status badge (Active / Stopped), keyword count, post count, centroid status
- Per-card actions: ⏸ Stop / ▶ Start / ⚙ Details / 🗑 Delete (with confirmation modal)
New Feed (/admin/feeds/new)
- Step 1 — AI Generation:
- Enter topic + language
- Click "Generate Seeds with AI" → calls GPT-4o → displays keyword cloud + sentence preview
- Animated per-keyword appearance
- Step 2 — Configuration:
- Feed ID (≤ 15 chars, Bluesky rkey limit enforced client + server side)
- Display name, description, language, embedding model, similarity threshold
- Toggle: "Publish to Bluesky automatically"
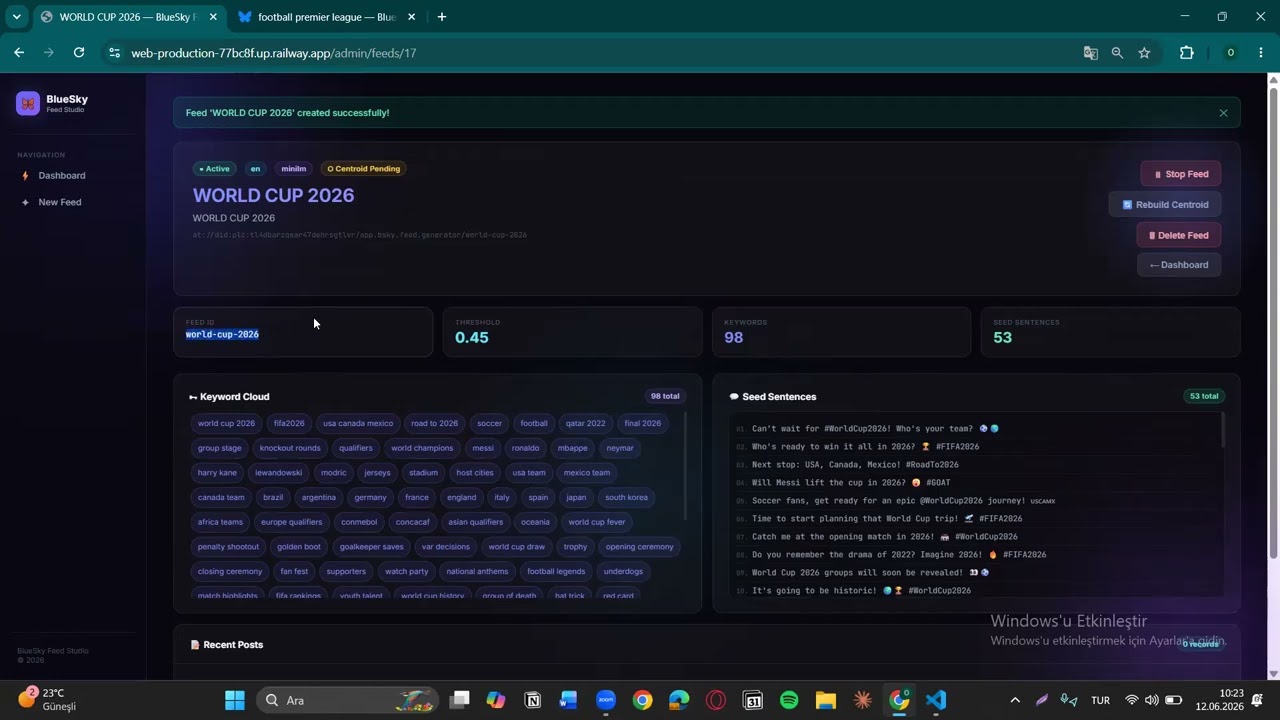
Feed Detail (/admin/feeds/<id>)
- Hero: feed name, status badges, AT URI
- Stats row: Feed ID, threshold, keyword count, seed sentence count
- Keyword cloud (animated pill tags)
- Seed sentence list (scrollable)
- Recent posts table with score bars
- Actions: Stop/Start, Rebuild Centroid, Publish to Bluesky (shown when AT URI is missing), Delete
Two Railway services in the same project, sharing one PostgreSQL database.
Web service (web)
- Builder: Railpack
- Install:
requirements.txt(Flask, atproto, openai — no torch) - Start:
waitress-serve --host=0.0.0.0 feed_generator.server:app - Handles: AT Protocol feed endpoints + admin panel
Worker service (BlueSky)
- Builder:
Dockerfile.worker - Installs CPU-only PyTorch +
requirements-nlp.txt - Start:
python data_collection/firehose_listener.py - Restart: Always
- Mount Railway Volume at
/hf_cacheto cache HuggingFace models (~440 MB BERTurk)
# 1. Clone and enter directory
git clone https://github.com/osmankantarcioglu/BlueSky.git
cd BlueSky
# 2. Virtual environment
python -m venv .venv
.venv\Scripts\Activate.ps1 # Windows
# source .venv/bin/activate # Linux/macOS
# 3. Install full NLP stack
pip install -r requirements-nlp.txt
pip install openai
# 4. Configure environment
copy .env.example .env
# Edit .env: set BSKY_HANDLE, BSKY_APP_PASSWORD, OPENAI_API_KEY
# Comment out DATABASE_URL to use local SQLite
# 5. Terminal 1 — Flask web server
python feed_generator/server.py
# 6. Terminal 2 — NLP worker (downloads BERTurk ~400MB on first run)
python data_collection/firehose_listener.py
# Admin panel: http://localhost:5000/admin| Variable | Service | Description |
|---|---|---|
BSKY_HANDLE |
web + worker | Bluesky handle (e.g. user.bsky.social) |
BSKY_APP_PASSWORD |
web + worker | Bluesky app password (Settings → App Passwords) |
FEED_DOMAIN |
web + worker | Public domain of Railway web service |
DATABASE_URL |
web + worker | PostgreSQL connection string (Railway auto-sets) |
DATABASE_PATH |
local dev | SQLite file path (default: data/feeds.db) |
OPENAI_API_KEY |
web + worker | GPT-4o seed generation in admin panel |
FLASK_SECRET_KEY |
web | Flask session secret (required for flash messages) |
HF_HOME |
worker | HuggingFace model cache path (Railway volume) |
LLM_PROVIDER |
web | openai (default) or anthropic |
CREATE TABLE feeds (
id SERIAL PRIMARY KEY,
feed_id VARCHAR(64) UNIQUE NOT NULL,
display_name VARCHAR(128) NOT NULL,
description TEXT DEFAULT '',
language VARCHAR DEFAULT 'tr', -- tr | en | multi
topic VARCHAR(256) NOT NULL,
at_uri VARCHAR, -- set after Bluesky registration
rkey VARCHAR,
keywords TEXT DEFAULT '[]', -- JSON list[str]
seed_sentences TEXT DEFAULT '[]', -- JSON list[str]
centroid TEXT, -- JSON list[float] (768-dim)
embedding_model VARCHAR DEFAULT 'berturk',
similarity_threshold FLOAT DEFAULT 0.30,
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP,
updated_at TIMESTAMP
);CREATE TABLE posts (
uri VARCHAR PRIMARY KEY,
cid VARCHAR NOT NULL,
author_did VARCHAR NOT NULL,
author_handle VARCHAR,
text TEXT NOT NULL,
feed_id INTEGER REFERENCES feeds(id) ON DELETE SET NULL,
domain_label VARCHAR, -- legacy: 'politics' | 'science'
domain_score FLOAT,
embedding TEXT, -- JSON: 768 floats
created_at TIMESTAMP NOT NULL,
indexed_at TIMESTAMP,
language VARCHAR,
like_count INTEGER DEFAULT 0,
repost_count INTEGER DEFAULT 0,
reply_count INTEGER DEFAULT 0,
feed_score FLOAT DEFAULT 0.0
);
CREATE INDEX ON posts (feed_score);
CREATE INDEX ON posts (feed_id, created_at);CREATE TABLE tracked_users (
did VARCHAR PRIMARY KEY,
handle VARCHAR NOT NULL,
display_name VARCHAR,
party VARCHAR,
stance VARCHAR DEFAULT 'unknown',
domain VARCHAR DEFAULT 'politics',
source VARCHAR DEFAULT 'csv',
created_at TIMESTAMP,
is_active BOOLEAN DEFAULT TRUE
);"Centroid Pending" on feed detail
The web server doesn't have NLP deps — centroid is built by the worker. Check Railway BlueSky worker logs for Building missing centroid for feed: <id>. Usually resolves within 60 seconds of the worker's next poll cycle.
Bluesky publish failed: rkey too long Bluesky AT Protocol enforces a 15-character maximum on record keys. Feed ID must be ≤ 15 chars. The form enforces this client-side; the backend validates and rejects longer IDs.
Feed shows no posts on Bluesky
- Verify centroid is built (feed detail shows "Centroid ✓")
- Check worker logs for
MultiPipeline ready: N feeds - Give it a few minutes — the firehose needs time to accumulate matching posts
- Try lowering
similarity_thresholdif the topic is niche
"Publish to Bluesky" button fails
Check that BSKY_HANDLE, BSKY_APP_PASSWORD, and FEED_DOMAIN are set in the web service Railway variables (not just the worker). Use a Bluesky App Password from Settings → App Passwords, not your login password.
Worker not picking up new feeds
The worker polls every 60 seconds for changes (Feed.updated_at > last_reload). Check Railway BlueSky worker logs for Feed config reloaded. If the worker crashed, redeploy it.
PostgreSQL transaction error on startup
Each table is created in its own db.atomic() savepoint. If one table fails (e.g. posts FK index on missing feed_id), others still succeed. Migrations (ALTER TABLE posts ADD COLUMN IF NOT EXISTS feed_id) run afterwards and fix schema gaps.
| Name |
|---|
| Osman Kantarcıoğlu |
| Selman Yılmaz |
| Berke Bölükkaya |
| Barış Güzeltaş |
| Batuhan |
| Talha Dönderici |
| Layer | Technology |
|---|---|
| Protocol | AT Protocol (atproto 0.0.55) |
| NLP embeddings | BERTurk · all-MiniLM-L6-v2 · paraphrase-multilingual-MiniLM |
| ML framework | PyTorch (CPU) + sentence-transformers + scikit-learn |
| AI seed generation | OpenAI GPT-4o (via openai SDK) |
| Language detection | langdetect |
| ORM | Peewee |
| Database (dev) | SQLite |
| Database (prod) | PostgreSQL (Railway) |
| Web framework | Flask + Waitress |
| Frontend | Vue 3 (CDN) + custom glassmorphism CSS |
| Deployment | Railway (web + worker services) |
| Container | Docker (worker only) |
| Language | Python 3.11 |