Author: Matthew Reinhart
The sports gambling industry is one of the fastest growing in America today. You cannot turn the television on to any sports channel without seeing an advertisement for one of the big sportsbooks. Whether it be Draftkings, FanDuel, BetMGM, Caesaers, Pointsbet or Barstool, the list goes on and on and the industry is only going to keep growing on a more national stage as more and more states move to legalize it. There is one sport that is widely considered the most difficult to bet on and predict within this industry and that is Major League Baseball. In a season with 162 games where powerhouses regularly lose to teams they are considered to be far superior to it can be awfully difficult to figure out who to bet on and to turn a profit. As GamblingSites hardest sports to bet on ranking says "Coming in as the most complicated sport to bet on is baseball. While I love betting on America’s pastime, it’s known to be the most demanding sport to win money. Baseball, unlike other major sports, is by far the most unpredictable sport to gamble on."
For even more information on the reality of this business probelm visit The Sports Geek. Here he breaks down six of the reasons why baseball can be very difficult to predict.
In the world of this project I am offering a better way to bet Major League Baseball. I offer people a more profitable way to bet the most unpredictable sport. In order to maximize returns, I ran a series of machine learning algorithms to model predictions for single games in a given MLB season. Accuracy is paramount in selecting our models, as we strive to minimize risk for our customers.
The data is mainly from Sportsipy with insights from Baseball-Referance as well.
To reproduce, click on either hyperlinks above, if you wish to access Sportsipy there are instructions as to how to get the data on the site as well as at the beginning of the "get any year" notebook in the "Data cleaning and exploration" folder on the repository. For the Baseball-Referance data after clicking on the link you can choose which year and which type of stats you would like to work with and then hit the drop down choose export it to csv option for easy use.
I set the win/loss outcome for the home team as the binary target variable, with 1 equaling a win for the home team and 0 equaling a win for the away team.
After that I used an iterative approach to build 6 predictive, classification models: Logistic regression, K-Nearest Neighbors, Decision Tree, Random Forest, Bagging classifier and XGBoost. We utilize hyperparameter tuning, cross-validation and scoring to select the highest performing, predictive models. This approach is applied to regular season as well as post season data.
After comparing metrics across all 6 of our models, the top 3 performers are Logistic Regression, K-Nearest Neighbors and Random Forest.
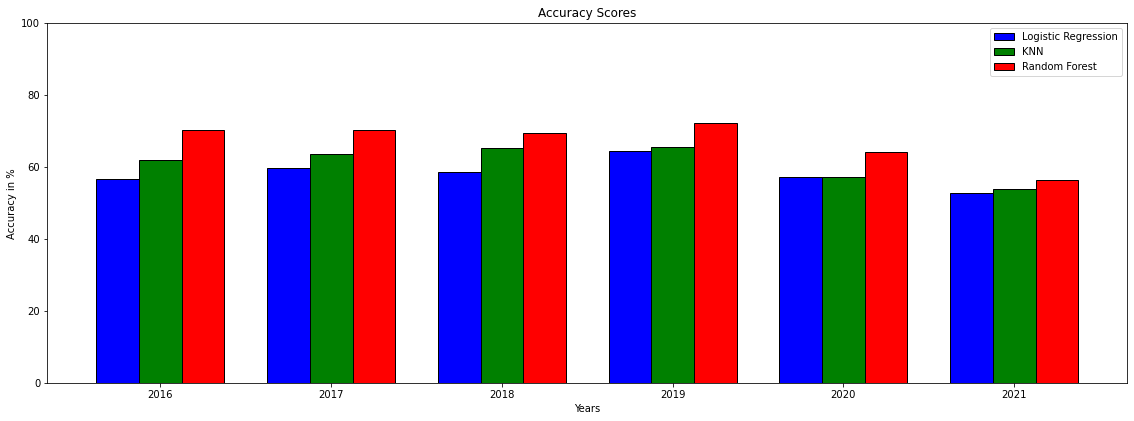
While all returned fairly encouraging results the Random Forest model was consistently coming out on top. In order to increase accuracy I built a function that would then drop games that were under 60% confidence meaning it would recommend you bet less games but the accuracy would also increase. This would help your overall profit.
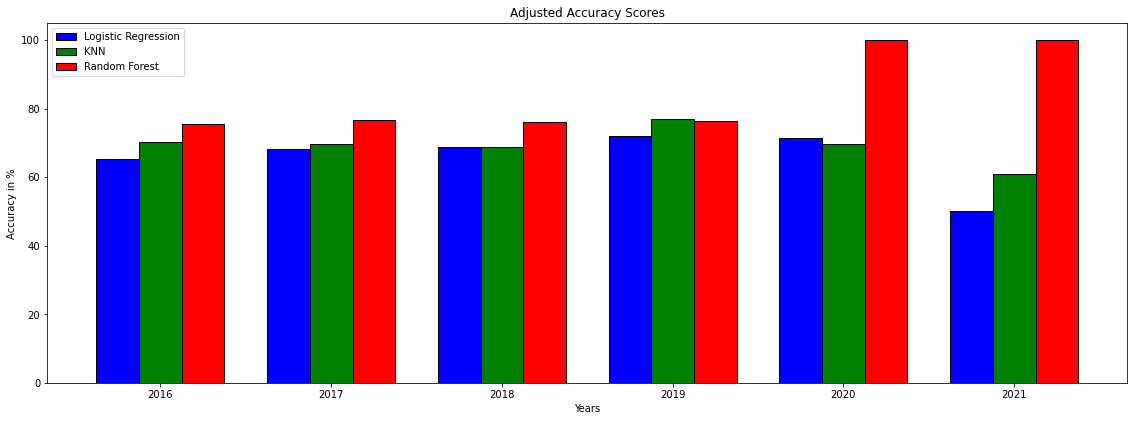 This still had Random Forest leading when it comes to accuracy but because of my new adjusted accuracy function it is also important to see how many games each model is selecting. That can be seen in the chart below:
This still had Random Forest leading when it comes to accuracy but because of my new adjusted accuracy function it is also important to see how many games each model is selecting. That can be seen in the chart below:
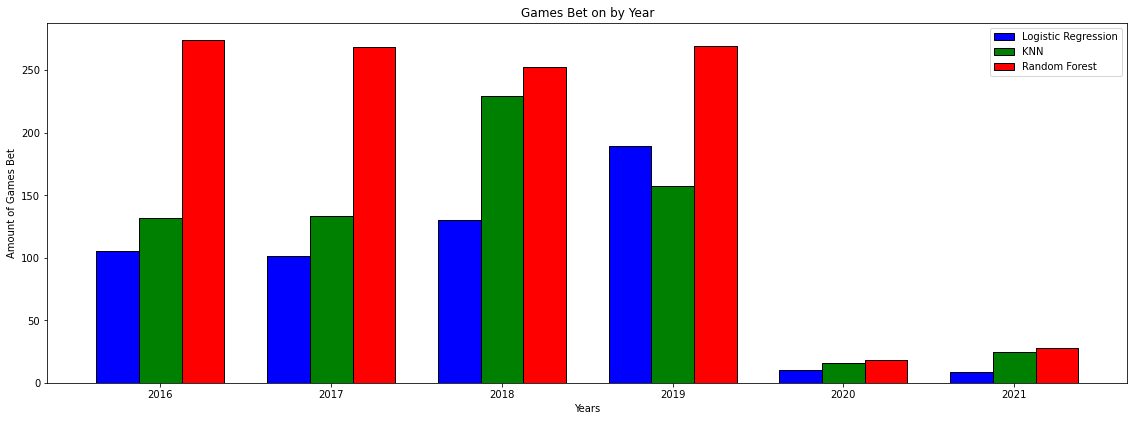
The first thing that pops out in most of these charts is 2020 and 2021. These years were heavily effected by the Covid pandemic and it can be assumed that normal years will look more like 2016-2019. Even so looking at this chart Random Forest has only further confirmed its standing as the superior model to use and that is the model that I decided to move forward with.
The only question to remain is using RFECV or PCA. The mean accuracy score using RFECV is 84.1% and the mean accuracy score using PCA is 83.6%. Then there is the number of games they tell you to bet on in an average season and that would be 184.8 for RFECV and 184 for PCA. This seems to have a slight edge towards RFECV however it should also be noted how much more computationally expensive it can be to use RFECV rather than PCA. In order to make sure these numbers were not overly skewed by the covid years I decided to look at the averages if we eliminated those years. Once that was done the mean accuracy scores were now 76.15% for RFECV and 76.33% for PCA. Once again incredibly close and now the games selected were 265.75 for RFECV and 264.5 for PCA.
The results of the Random Forest are clearly the best so that is the model that I would recommend is used in this expirement. I would also recommend using PCA for the model rather than RFECV feature selection as PCA is much less computationally expensive and the accuracy scores and amount of games picked are nearly identical.
For next steps I would like to:
- Dive deeper into games on a more individual level in order to value starting pitching to a higher level
- Integrate Moneyline data so I can further identify value
- Look at adjusting bet sizing based on value potentially using the famous Kelly Criterion
Please look through my main Jupyter Notebook and check out my Presentation Deck
If you have any questions feel free to contact me: Mreinhart1021@gmail.com
├── README.md <- The top-level README for reviewers of this project
├── Main_Notebook.ipynb <- Narrative documentation of analysis in Jupyter Notebook
├── Project_Presentation.pdf <- PDF version of project presentation
├── Modeling_functions.py <- Python script with all model related functions to be called in MAIN Notebook
├── data_collection_functions.py <- Raw .csv source files from Kaggle
├── data <- Folder of cleaned, exported .csv files to import in MAIN Notebook
├── Data_cleaning_and_exploration <- Folder of separate Notebooks showing collection and cleaning of data
├── Modeling <- Folder of separate Notebooks showing completed models on data
└── Obselete <- Older Notebooks that aren't necessary for final deliverables