O JusDataPredict analisa uma tese jurídica em um determinado juízo e fornece uma probabilidade de êxito, além de apresentar as decisões mais similares para análise de consistência jurisprudencial.

O Problema
A tomada de decisões no campo jurídico — seja ao propor uma ação, negociar um acordo ou elaborar uma defesa — é um processo inerentemente arriscado e demorado. Advogados e clientes dependem da interpretação de um vasto e disperso histórico de decisões judiciais (jurisprudência), buscando previsibilidade em um ambiente de incertezas.
A Solução
O JusDataPredict traduz a complexidade legal em probabilidade estatística. Utilizando um dataset de decisões judiciais, a ferramenta emprega modelos de Machine Learning para calcular a probabilidade de sucesso de uma causa e utiliza NLP para encontrar os precedentes mais relevantes, transformando dados históricos em inteligência estratégica.
Funcionalidades-Chave:
-
Predição de Risco: Calcula a probabilidade de êxito de uma tese jurídica com base no histórico de decisões de um juízo específico.
-
Classificação de Risco: Traduz a probabilidade em um nível de risco de fácil compreensão ("Baixo", "Médio" ou "Alto").
-
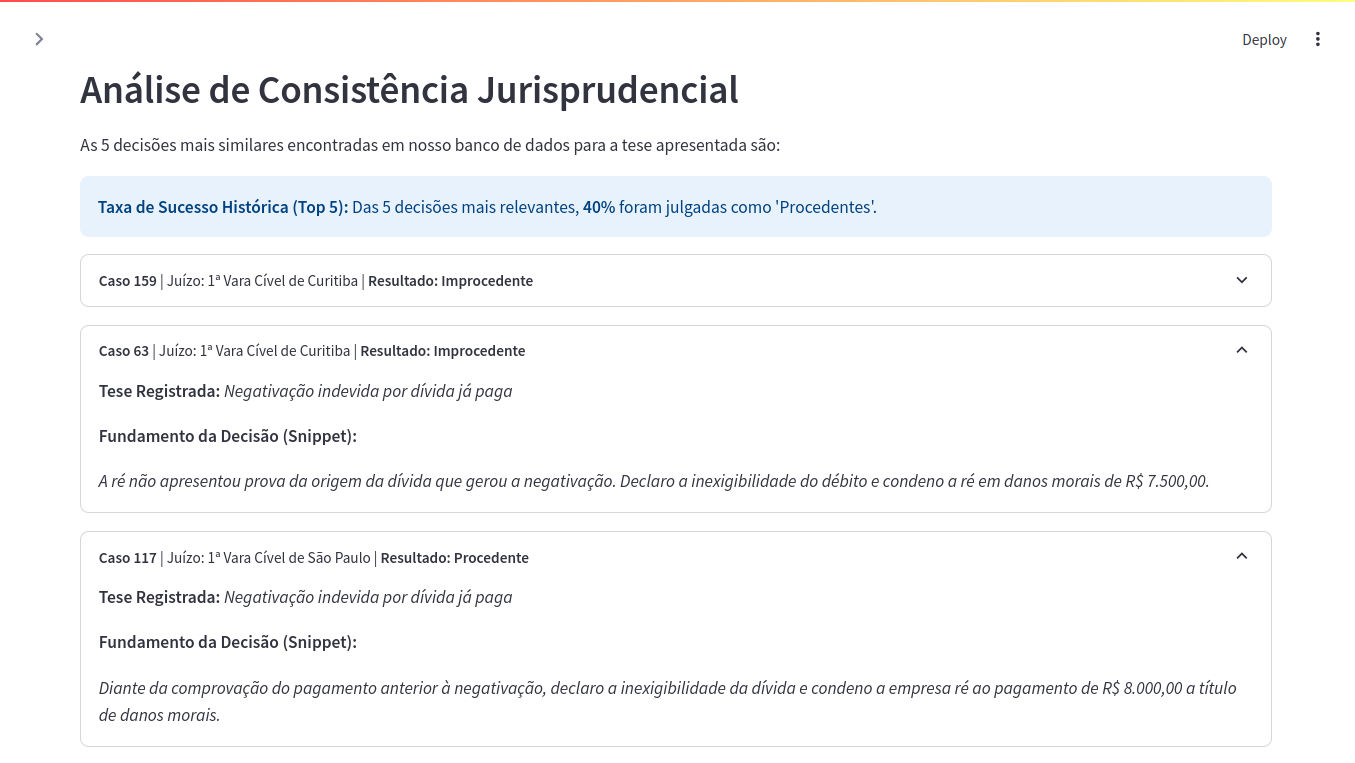
Análise de Consistência: Utiliza similaridade de cossenos para buscar e ranquear as 5 decisões mais parecidas com o caso em análise, permitindo ao advogado verificar se a jurisprudência local é consistente ou divergente.
Interface Interativa: Um painel de controle simples, construído com Streamlit, para facilitar a entrada de dados e a visualização dos resultados.
Tecnologias Utilizadas
Este projeto foi construído com as seguintes tecnologias:
- Linguagem: Python 3.9+
- Framework Web: Streamlit
- Machine Learning: Scikit-learn
- Manipulação de Dados: Pandas
- Serialização de Modelos: Joblib
Estrutura do Projeto
jusdatapredict/
│
├── data/
│ └── jurisprudencia.csv # Dataset (sintético, neste MVP)
│
├── models/ # Modelos e artefatos salvos pelo script de treino
│ ├── risk_prediction_model.joblib
│ ├── similarity_vectorizer.joblib
│ ├── cosine_similarity_matrix.joblib
| ├── label_encoder.joblib
│ └── jurisprudencia_df.joblib
│
├── scripts/
│ └── train_model.py # Script para treinar e salvar os modelos de IA
│
├── app.py # Aplicação principal do Streamlit
│
├── requirements.txt # Dependências do projeto
│
└── README.md # Documentação do projeto
Siga os passos abaixo para configurar e rodar o projeto em sua máquina local.
python -m venv .venvsource .venv/bin/activatepip install -r requirements.txtGere o dataset sintético:
Este MVP utiliza um dataset gerado por script para simular dados reais. Execute o script de criação de dados:
python create_data.pyIsso criará a pasta data/ com o arquivo jurisprudencia.csv.
Treine os modelos de Machine Learning:
Entre na pasta scripts/e execute o código:
python train_model.pyO script irá processar os dados, treinar os modelos de predição e similaridade, e salvá-los na pasta models/.
Execute a aplicação Streamlit:
Com os modelos treinados, você já pode iniciar a aplicação.
streamlit run app.pyA aplicação será aberta automaticamente no seu navegador padrão!
Módulo de Predição de Risco
- Input: O advogado insere a Tese Jurídica e seleciona o Juízo.
- Pré-processamento: Os textos são combinados e transformados em um vetor numérico pelo
TfidfVectorizer, que foi treinado previamente. - Predição: O vetor é então alimentado no modelo de Regressão Logística treinado, que calcula a probabilidade da classe "Procedente".
- Output: A probabilidade é exibida como uma porcentagem e classificada como "Baixo", "Médio" ou "Alto Risco".
Módulo de Análise de Consistência
- Input: A Tese Jurídica inserida pelo usuário.
- Vetorização: A tese é transformada em um vetor numérico usando o mesmo TfidfVectorizer (focado apenas em teses).
- Cálculo de Similaridade: A similaridade de cossenos é calculada entre o vetor da nova tese e todos os vetores de teses do dataset original.
- Ranking: O sistema identifica os 5 vetores com a maior pontuação de similaridade.
- Output: As 5 decisões correspondentes são recuperadas e exibidas, permitindo uma análise contextual da jurisprudência.
Após iniciar a aplicação, você verá uma interface na barra lateral esquerda:
- Selecione um Juízo da lista.
- Descreva a Tese Jurídica no campo de texto.
- Clique no botão "Analisar Risco e Consistência".
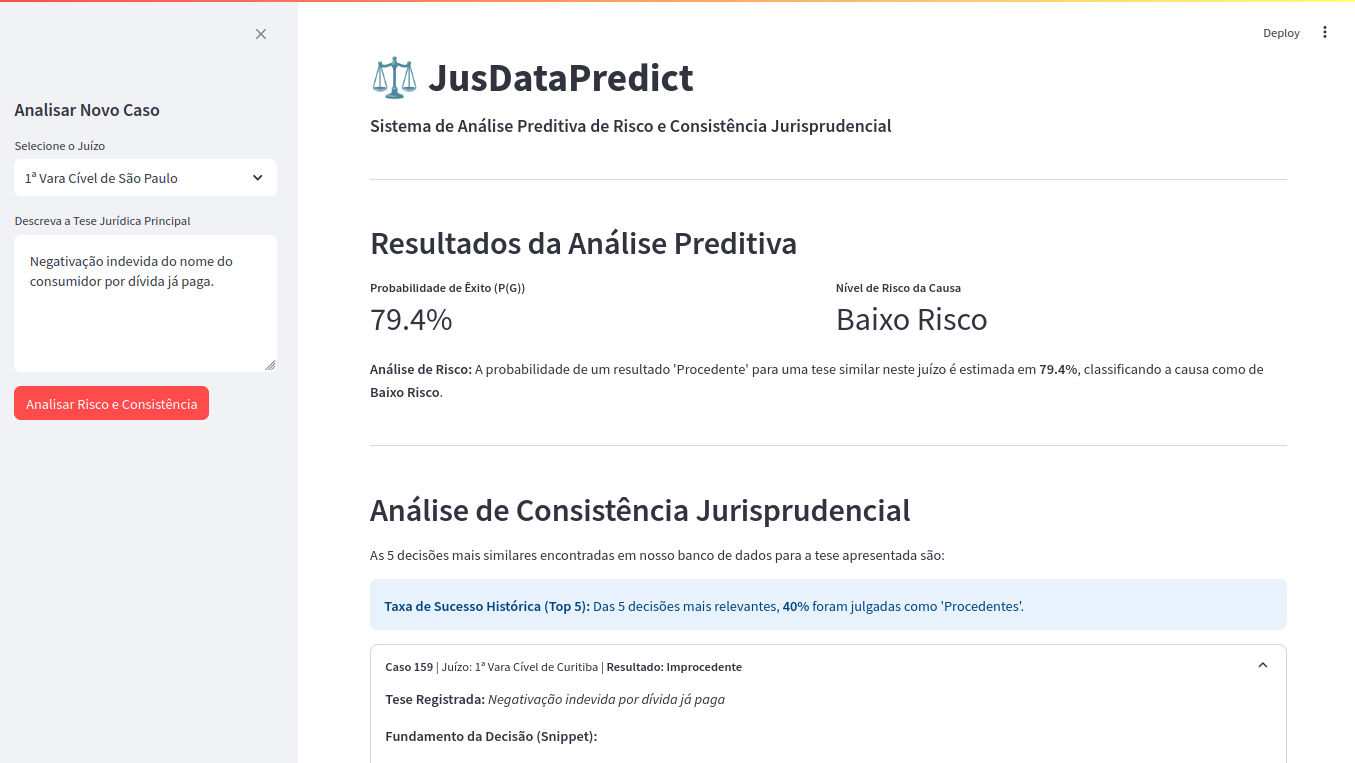
O painel principal será atualizado com a probabilidade de êxito, o nível de risco e uma lista expansível com as 5 decisões mais relevantes para o seu caso.
Este projeto está licenciado sob a Licença MIT. Consulte o arquivo LICENSE para mais detalhes.