论文地址:https://arxiv.org/abs/1706.03762
发表时间:2017年6月12号
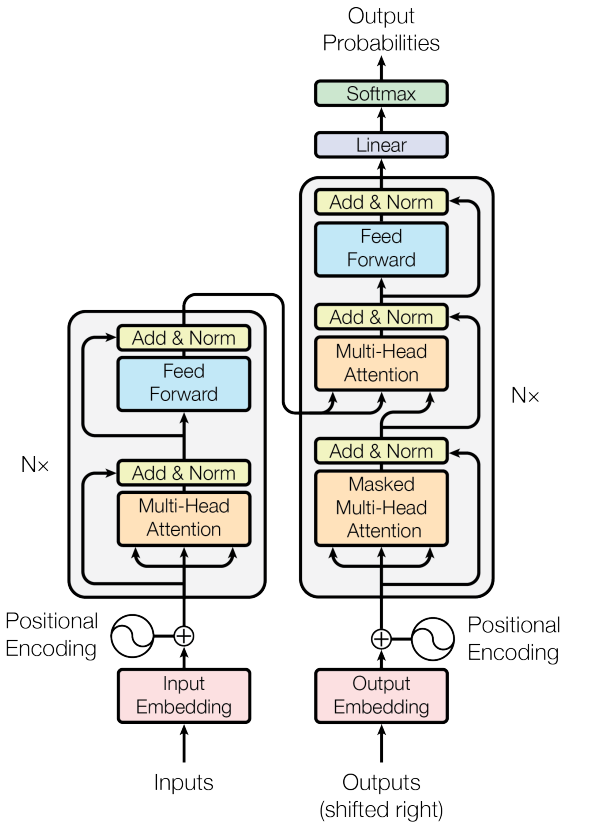
模型的左侧为Encoder,将输入序列x=(x1,x2,...,xn)映射到z=(z1,z2,...,zn)。z作为Decoder的Multi-Head Attention输入。给定z,Decoder产生输出序列y=(y1,y2,...,ym),每次产生一个点。Decoder是一个自回归模型,即每次Decoder的输入是上一个step的输出。
举例:
利用Transformer完成中文到英文的翻译,例如“机器学习”→“Machine Learning”
Encoder的输入是“机器学习”对应的Embedding,然后输出隐变量z
第一步,我们向Decoder输入BOS,代表语句开头,Decoder通过输入的字符以及Encoder输出的隐变量z,输出“Machine”;
第二步,"Machine"作为Decoder的输入,Decoder输出“Learning”;
第三步,翻译结束
自注意力机制是一种能够通过关联一个序列当中不同位置的点而形成这个序列的表征的注意力机制。自注意力机制的query``key``value均来自同一个输入序列。
使用compatibility function来计算给定query与每个key的相似度,以相似度作为权重来加权求和所有value。这里使用的compatibility function是Scaled Dot-Product,对应的attention的计算方法如下:
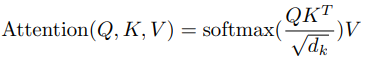
这里采用了dk来Scaled的原因是:当dk很大时,点积的结果会非常大,这样会使得softmax函数的梯度变得非常小。所以考虑到梯度问题,我们需要去控制点积结果的范围。
原文采用八个更小的不同的并行计算的注意力层来代替一个单独的大的注意力层。这样,不同的注意力层类似于不同的卷积通道,他们关注了不同的特征。最后再集成这8个注意力层的结果来综合最后的注意力输出。
- Encoder-Attention-Decoder的结果
- Encoder中的self-attention
- Decoder中的masked self-attention
- 每层网络的计算复杂度大大降低,相比于RNN和CNN
- 整个网络可以高度并行化
- 注意力机制能够关注到一些跨越整个序列的特征
Batch Norm: 计算一个批内样本的均值和方差,以及训练两个参数λ和β。
Layer Norm: 计算一个样本的feature求均值和方差。
一般来说,现在样本点数据很多情况下都是一个序列,序列的每个点都有特征向量,样本与样本之间的序列长度不尽相同。在这种情况下,batch norm均值和方差的抖动会非常大,尤其是在计算全局的均值和方差,可能会跟一个批的均值方差差距很大。Layer Norm则不会出现这种情况。