
本文件已与英文版 README 同步(同步日期:2026-04-20),如有差异请以英文版为准。
目录
💖 Browser4:为 AI 打造的闪电般快速、协程安全(coroutine-safe)的浏览器引擎 💖
- 👽 浏览器智能体(Browser Agents) — 能在浏览器中推理、规划并执行端到端任务的自主智能体。
- 🤖 浏览器自动化 — 面向工作流、导航与数据提取的高性能自动化能力。
- ⚙️ 机器学习智能体 — 在复杂页面上学习字段结构,无需消耗 token。
- ⚡ 极致性能 — 完全协程安全;支持单机每天访问 100k ~ 200k 复杂页面。
- 🧬 数据抽取 — 结合 LLM、ML 与选择器,在复杂页面中获得干净数据。
# 打开新浏览器窗口
browser4-cli open
# 导航到页面
browser4-cli goto https://playwright.dev
# 查看页面快照,注意交互节点上的 eN 标签
browser4-cli snapshot
# 使用快照中的 refs 进行交互
browser4-cli click e15
browser4-cli type e15 "Hello World"
browser4-cli press e15 Enter
browser4-cli keydown Shift
browser4-cli mousemove 150 300
browser4-cli mousewheel 0 100
browser4-cli keyup Shift
# 截图并保存到本地
browser4-cli screenshot
# 使用自定义服务地址
browser4-cli open --server http://localhost:9090
# 在同一进程中执行多条命令
browser4-cli batch "open https://playwright.dev" "snapshot"
# 遇到第一条失败命令即停止
browser4-cli batch --bail "open https://playwright.dev" "click e1" "screenshot"
# 通过 stdin 以 JSON 形式传入批处理命令
echo '[
["open", "https://playwright.dev"],
["snapshot"],
["click", "e1"],
["screenshot", "--filename=result.png"]
]' | browser4-cli batch --json
# 使用完成后关闭会话
browser4-cli close🎬 YouTube:
📺 Bilibili: https://www.bilibili.com/video/BV1fXUzBFE4L
前置要求:Java 17+
-
克隆仓库
git clone https://github.com/platonai/browser4.git cd browser4 -
配置你的 LLM API key
编辑 application.properties 并添加你的 API key。
-
构建项目
./mvnw -DskipTests
-
运行示例
./mvnw -pl examples/browser4-examples exec:java -D"exec.mainClass=ai.platon.pulsar.examples.agent.Browser4AgentKt"如果你在 Windows 上遇到编码问题:
./bin/run-agent-examples.ps1
在
browser4-examples模块中探索并运行示例,直观看到 Browser4 的能力。 Java 兼容示例已移除,请改用 Kotlin API、SDK 或 CLI 工具。
Docker 部署见 Docker Hub repository。
Windows 用户:你也可以将 Browser4 构建为独立 Windows 安装包。详见 Windows Installer Guide。
Browser4 CLI 是一个强大的命令行接口,可直接进行浏览器控制和自动化,面向人类用户与 AI agents。 它提供简单语法,让你无需写代码即可完成复杂浏览器交互。
Browser4 CLI 与 Playwright 兼容,支持导航、交互、数据提取等广泛命令。 它可以用于脚本、终端会话,或通过 SKILLS 集成进 AI agents。
# 安装最新 Unix CLI(包含 Browser4.jar 兜底运行时)
curl -fsSL https://raw.githubusercontent.com/platonai/Browser4/master/sdks/browser4-cli/install.sh | bash
# Windows:保留 Browser4 仓库以支持 localhost Maven 自动启动;Browser4.jar 仍是兜底运行时
New-Item -ItemType Directory -Force -Path "$env:USERPROFILE\.browser4\lib" | Out-Null
Invoke-WebRequest 'https://github.com/platonai/Browser4/releases/latest/download/Browser4.jar' -OutFile "$env:USERPROFILE\.browser4\lib\Browser4.jar"
git clone https://github.com/platonai/Browser4.git
cd Browser4\sdks\browser4-cli
cargo install --path . --locked
# 打开新浏览器窗口
browser4-cli open
# 导航到页面
browser4-cli goto https://playwright.dev
# 查看页面快照,注意交互节点上的 eN 标签
browser4-cli snapshot
# 使用快照中的 refs 进行交互
browser4-cli click e15
browser4-cli type e15 "Hello World"
browser4-cli press e15 Enter
browser4-cli keydown Shift
browser4-cli mousemove 150 300
browser4-cli mousewheel 0 100
browser4-cli keyup Shift
# 截图并保存到本地
browser4-cli screenshot
# 使用自定义服务地址
browser4-cli open --server http://localhost:9090
# 在同一进程中执行多条命令
browser4-cli batch "open https://playwright.dev" "snapshot"
# 遇到第一条失败命令即停止
browser4-cli batch --bail "open https://playwright.dev" "click e1" "screenshot"
# 通过 stdin 以 JSON 形式传入批处理命令
echo '[
["open", "https://playwright.dev"],
["snapshot"],
["click", "e1"],
["screenshot", "--filename=result.png"]
]' | browser4-cli batch --json
# 使用完成后关闭会话
browser4-cli close从源码构建 CLI:
Browser4 CLI 为 AI agents 通过 SKILLS + CLI 使用而设计。
可理解自然语言指令并执行复杂浏览器工作流的自主智能体。
val agent = AgenticContexts.getOrCreateAgent()
val task = """
1. go to amazon.com
2. search for pens to draw on whiteboards
3. compare the first 4 ones
4. write the result to a markdown file
"""
agent.run(task)低层浏览器自动化与数据提取,支持细粒度控制。
特性:
- 同时支持实时 DOM 访问与离线快照解析
- 直接且完整的 Chrome DevTools Protocol(CDP)控制,协程安全
- 精确元素交互(点击、滚动、输入)
- 基于 CSS 选择器/XPath 的快速数据提取
val session = AgenticContexts.getOrCreateSession()
val agent = session.companionAgent
val driver = session.getOrCreateBoundDriver()
// 加载输入 URL 对应的初始页面
var page = session.open(url)
// 用自然语言驱动浏览器动作
agent.act("scroll to the comment section")
// 从实时 DOM 中读取首个匹配评论节点
val content = driver.selectFirstTextOrNull("#comments")
// 将页面快照解析为内存文档,进行离线解析
var document = session.parse(page)
// 一次性将 CSS 选择器映射为结构化字段
var fields = session.extract(document, mapOf("title" to "#title"))
// 让 companion agent 执行多步导航/搜索流程
val history = agent.run(
"Go to amazon.com, search for 'smart phone', open the product page with the highest ratings"
)
// 将更新后的浏览器状态捕获回 PageSnapshot
page = session.capture(driver)
document = session.parse(page)
// 从捕获快照中提取更多字段
fields = session.extract(document, mapOf("ratings" to "#ratings"))适用于高复杂度数据抽取流水线,典型场景包含数十个实体、每个实体数百个字段。
优势:
- 相比传统方法,可多提取 10 倍实体与 100 倍字段
- 结合 LLM 智能与精准 CSS 选择器/XPath
- 类 SQL 语法,学习成本低
val context = AgenticContexts.create()
val sql = """
select
llm_extract(dom, 'product name, price, ratings') as llm_extracted_data,
dom_first_text(dom, '#productTitle') as title,
dom_first_text(dom, '#bylineInfo') as brand,
dom_first_text(dom, '#price tr td:matches(^Price) ~ td, #corePrice_desktop tr td:matches(^Price) ~ td') as price,
dom_first_text(dom, '#acrCustomerReviewText') as ratings,
str_first_float(dom_first_text(dom, '#reviewsMedley .AverageCustomerReviews span:contains(out of)'), 0.0) as score
from load_and_select('https://www.amazon.com/dp/B08PP5MSVB -i 1s -njr 3', 'body');
"""
val rs = context.executeQuery(sql)
println(ResultSetFormatter(rs, withHeader = true))示例代码:
通过并行浏览器控制与智能资源优化获得极致吞吐。
性能:
- 单机每天访问 10k ~ 20k 复杂页面
- 并发会话管理
- 阻断无关资源,加速页面加载
val args = "-refresh -dropContent -interactLevel fastest"
val blockingUrls = listOf("*.png", "*.jpg")
val links = LinkExtractors.fromResource("urls.txt")
.map { ListenableHyperlink(it, "", args = args) }
.onEach {
it.eventHandlers.browseEventHandlers.onWillNavigate.addLast { page, driver ->
driver.addBlockedURLs(blockingUrls)
}
}
session.submitAll(links)🎬 YouTube:

📺 Bilibili: https://www.bilibili.com/video/BV1kM2rYrEFC
基于自监督/无监督机器学习的自动化、大规模、高精度字段发现与抽取:无需 LLM API、无需 token、确定且快速。
能力:
- 高精度学习商品/详情页上的全部可抽取字段(通常几十到上百个)。
- 当 Browser4 在 GitHub 达到 10K stars 时开源。
为什么不只用 LLM?
- LLM 抽取会带来延迟、成本与 token 限制。
- 基于 ML 的自动抽取本地可复现,可扩展到 100k+ ~ 200k 页/天。
- 可组合使用:自动抽取负责结构化基线,LLM 负责语义增强。
快捷命令(PulsarRPAPro):
# 注意:需要 MongoDB
curl -L -o PulsarRPAPro.jar https://github.com/platonai/PulsarRPAPro/releases/download/v4.6.0/PulsarRPAPro.jar集成状态:
- 当前可通过配套项目 PulsarRPAPro 使用。
- 计划提供 Browser4 原生 API 暴露;请关注后续版本发布。
关键优势:
- 高精度:>95% 字段发现率;多数已测站点字段精度 >99%(指示性数据)。
- 对选择器漂移与 HTML 噪声更鲁棒。
- 零外部依赖(无需 API key),规模化成本更优。
- 可解释:生成选择器与 SQL 透明且可审计。
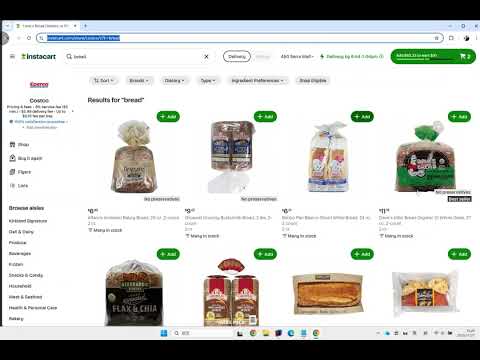
👽 使用机器学习智能体进行数据抽取:

(即将推出:更丰富的仓库内示例与直接 API 挂钩。)
| 模块 | 说明 |
|---|---|
browser4-core |
核心引擎:会话、调度、DOM、浏览器控制 |
browser4-agentic |
智能体实现、MCP 与技能注册 |
browser4-rest |
Spring Boot REST 层与命令端点 |
browser4-agents |
智能体与爬虫编排及产品打包 |
sdks |
Rust 实现的 CLI,支持 SKILLS |
examples |
可运行示例与演示工程 |
browser4-tests |
E2E 与重型集成/场景测试 |
状态说明:[已提供] 在仓库中,[实验中] 正在迭代,[规划中] 暂未在仓库中,[指标] 性能目标值。
- [已提供] 面向问题求解的自主浏览器智能体
- [已提供] 并行智能体会话
- [实验中] LLM 辅助的页面理解与抽取
- [已提供] 基于工作流的浏览器动作
- [已提供] 协程安全的精确控制(滚动、点击、抽取)
- [已提供] 灵活的事件处理与生命周期管理
- [已提供] 一行命令式数据抽取
- [已提供] 面向 DOM/内容的 X-SQL 扩展查询语言
- [实验中] 结构化 + 非结构化混合抽取(LLM + ML + 选择器)
- [已提供] 高效并行页面渲染
- [已提供] 抗封锁设计与智能重试
- [指标] 普通硬件下达到 100,000+ 复杂页面/天
- [实验中] 先进反机器人技术
- [已提供] 通过
PROXY_ROTATION_URL进行代理轮换 - [已提供] 弹性调度与质量保障
- [已提供] 简洁 API 集成(REST、原生、文本命令)
- [已提供] 丰富配置分层
- [已提供] 清晰的结构化日志与指标
- [已提供] 本地文件系统与 MongoDB 支持(可扩展)
- [已提供] 全面日志与透明度
欢迎加入社区获取支持、反馈问题并参与协作!
- GitHub Discussions:与开发者和用户交流。
- Issue Tracker:报告 bug 或提交功能请求。
- Social Media:关注我们的最新动态。
我们欢迎贡献!详见 CONTRIBUTING.md。
完整文档可在 docs/ 目录和 GitHub Pages site 查看。
Details
将环境变量 PROXY_ROTATION_URL 设置为代理服务商提供的轮换 URL:
export PROXY_ROTATION_URL=https://your-proxy-provider.com/rotation-endpoint每次访问该轮换 URL 时,应返回一个或多个新的代理 IP。 如需该类型 URL,请联系你的代理服务商。
Apache 2.0 License。详见 LICENSE。