2015
http://dx.doi.org/10.1016/j.ejor.2015.05.030
A credit score is a model-based estimate of the probability that a borrower will show some undesirable behavior in the future.
- Esse comportamento não é, necessariamente, um default (inadimplência). Pode ser qualquer padrão indesejável de acordo com as características do cliente.
Credit scoring is concerned with developing empirical models to support decision making in the retail credit business
- É uma modelagem, por definição, empírica, já que a definição de comportamento indesejado pode variar de acordo com as características do mercado, do cliente, e/ou da empresa.
(...) there have been several advancements including novel learning methods, performance measures and techniques to reliably compare different classifiers, which the credit scoring literature does not reflect.
Os avanços recentes cobrem três frentes:
- (i) Novos algoritmos de classificação para o desenvolvimento de scorecards (e.g., extreme learning machines, rotation forest, etc.);
- (ii) Novas métricas de performance para avaliar scorecards(e.g., H-measure ou partial Gini coefficient);
- (iii) Testes de hipótese estatísticos para comparar performance de scorecards
Much literature explores the development, application, and evaluation of predictive decision support models in the credit industry. Such models estimate credit worthiness based on a set of explanatory variables. Corporate risk models employ data from balance sheets, financial ratios, or macro-economic indicators, whereas retail models use data from application forms, customer demographics, and transactional data from the customer history. The Basel II Capital Accord requires financial institutions to estimate, respectively, the probability of default (PD), the exposure at default (EAD), and the loss given default (LGD).
A maioria dos estudos se apoia em uma única métrica de performance ou em métricas do mesmo tipo. Em geral, pode-se dividir as métricas de performance em três tipos:
- Aquelas que avaliam o poder discriminatório do scorecard (e.g., AUC);
- Aquelas que avaliam a acurácia das previsões probabilísticas do scorecard (e.g., Brier Score);
- E aquelas que avaliam the exatidão das previsões categóricas do scorecard (e.g., classification error).
Testes de hipótese estatísticos são frequentemente negligenciados ou usados incorretamente. Erros comuns incluem o uso de testes paramétricos (e.g., t-test) ou realização de comparações múltiplas sem controlar pelo nível de erro na família (shown by a ‘P’ in the last column of Table 1). As abordagens são inapropriadas porque os pressupostos de testes paramétricos são violados em comparações de classificadores. De forma semelhante, comparações pairwise sem ajuste de p-value aumentam a probabilidade de erros do Tipo-I além do nivel de α.
A scorecard is a classification model that results from applying a classification algorithm to a dataset of past loans.
Já é sabido que o desbalanceamento de classes dificulta os esforços de classificação. Em particular, um classificador pode vir a dar muita ênfase à classe majoritária enquanto menospreza o grupo minoritário. Abordagens de reamostragem como under-/oversampling ou SMOTE foram propostas como uma possível solução.
Para os fins do estudo feito, eles não rebalancearam os datasets por três motivos:
- O objetivo era examinar a performance relativa entre diferentes classificadores. Se o desbalanceamento de classes impactasse todos os classificadores da mesma maneira, isso afetaria o nível absoluto de desempenho observado, mas não as diferenças relativas de desempenho entre os classificadores. Se, por outro lado, alguns classificadores fossem particularmente robustos em relação ao desequilíbrio de classes, então tal característica seria um indicador relevante quanto ao mérito do classificador. A reamostragem mascararia as diferenças associadas à robustez/sensibilidade ao desequilíbrio.
- A prevalência de reamostragem no mundo corporativo é debatível. Isto também sugere que é preferível dar uma imagem imparcial do desempenho dos algoritmos.
- Por fim, a maioria dos datasets exibia apenas um desbalanceamento moderado. Só se observa um desbalanceamento mais severo em dois dos maiores conjuntos de dados (UK and GMC). Devido ao seu tamanho, esses dados ainda incluem uma quantidade considerável de defaults, de modo que os algoritmos ainda deveriam conseguir identificar os padrões.
- Percentage correctly classified (PCC): fração das observações que foi corretamente classificada. Requer previsões discretas, que podem ser obtidas ao se comparar p(+|x) a um threshold τ e atribuir x à classe positiva se p(+|x) > τ , e à classe negativa caso contrário. Na prática, escolhas apropriadas de τ dependem dos custos associados à concessão de credito a clientes inadimplentes ou à rejeição de bons clientes. Na ausência de tal informação, computa-se τ (para cada dataset) de modo que a fração de exemplos classificados como positivos seja igual à fração de positivos no conjunto de treino.
- Brier Score (BS): erro médio quadrático entre p(+|x) e uma variável de resposta binária.
- Kolmogorov–Smirnov statistic (KS): diferença máxima entre as curvas de score cumulativas das classes positiva e negativa.
- Area Under ROC Curve (AUC): corresponde à probabilidade de um caso positivo aleatoriamente escolhido receber um score mais alto que um caso negativo aleatoriamente escolhido.
- The PCC and the KS embody a local scorecard assessment. They measure accuracy relative to a single reference point. The AUC and the BS perform a global assessment in that they consider the whole score distribution. The former uses relative (to other cases) score ranks. The latter considers absolute score values. A global perspective assumes implicitly that all thresholds are equally probable. This is not plausible in credit scoring (e.g.,Hand, 2005).
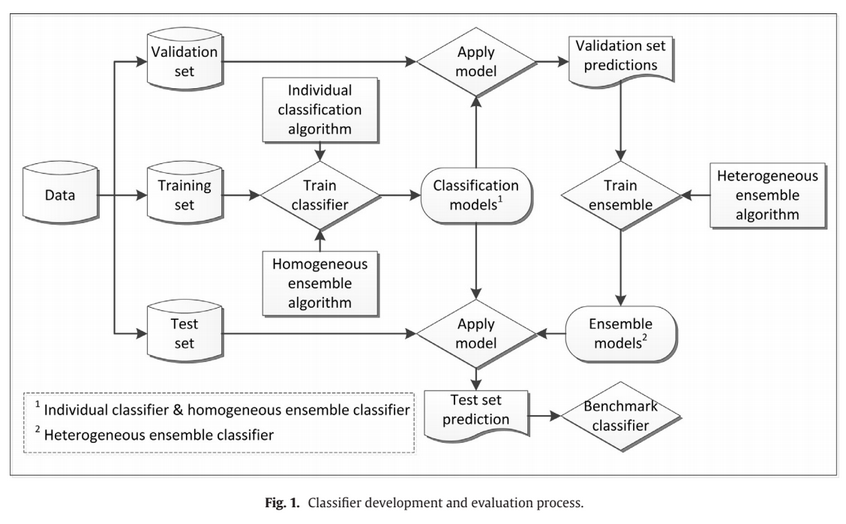
An important pre-processing decision concerns data partitioning. We use Nx2-fold Cross-Validation (Dietterich, 1998).
This involves:
- randomly splitting a data set in half,
- using the first and second half for model building and evaluation, respectively,
- switching the roles of the two partitions, and
- repeating the two-fold validation N times. Compared to using a fixed training and test set, multiple repetitions of two-fold cross-validation give more robust results, especially when working with small data sets. We set N depending on data set size.
Melhores classificadores (11 primeiros) usaram ensemble heterogêneo
Melhor classificador individual foi ANN, mas ficou atrás de vários ensembles heterogêneos
ANN foi melhor que Regressão Logística, que é o padrão da indústria
Some authors have taken the similarity between LR and advanced methods such as ANN as evidence that complex classifiers do not offer much advantage over simpler methods. We do not agree with this view. Our results suggest that comparisons among individual classifiers are too narrow to shed light on the value of advanced classifiers.
Métodos mais avançados, entretanto, não necessariamente melhoram a acurácia
Neither of the augmented classifiers improves upon its ancestor
Não há dúvida de que os ensembles dinâmicos foram os classificadores mais complexos usados no estudo. Apesar disso, independentemente da métrica de performance empregada, suas previsões foram consideravelmente menos precisas que as de alternativas mais simples, incluindo RL e outras tecnicas tradicionais.
Observa-se também que a abordagem simples de se combinar as previsões de todos os modelos-base via média não-ponderada atinge performance competitiva.
Baseando-se em comparações pareadas entre classificadores de interesse, concluí-se que:
- RL fornece previsões menos acuradas que qualquer dos demais;
- HCES-Bag (Hill-climbing ensemble selection with bootstrap sampling) fornece previsões mais acuradas que qualquer dos demais; e
- os resultados empíricos não permitem concluir se RF e ANN têm performances significantemente diferentes.
Foi calculado o custo de erros de classificação de um scorecard como a soma ponderada da taxa de falsos positivos e da taxa de falsos negativos (Specificity), usando como ponderação os seus custos de decisão correspondentes.
De modo a simular diferentes cenários, foram consideradas 25 diferentes razões de custo no interevalo [1:2,..., 1:50], sempre assumindo que é mais custoso fornecer crédito para um cliente arriscado do que rejeitar um bom cliente.
The most accurate classifier loses its advantage when the cost of misclassifying bad credit risks increases. This shows that the link between (statistical) accuracy and business value is far from perfect. The most accurate classifier does not necessarily give the most profitable scorecard.
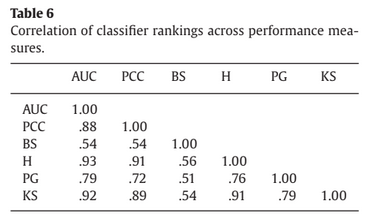
Com base na tabela 6, os autores recomendam que estudos futuros usem ao menos três medidas distintas de performance: AUC, PG (Partial Gini Index), e BS. O argumento feito é que PG e BS oferecem uma perspectiva adicional sobre o poder preditivo e, portanto, deveriam ser parte rotineira de comparações entre scorecards.
Não sei o quanto eu concordo com isso. O artigo dado como referência sobre o PG só recebeu duas citações em quase 8 anos e foi publicado em um periódico bem suspeito.
We find some advanced methods to perform extremely well on our credit scoring data sets, but never observe the most recent classifiers to excel. ANNs perform better than ELMs, RF better than RotFor, and dynamic selective ensembles worse than almost all other classifiers.
This may indicate that progress in the field has stalled (e.g.,Hand, 2006), and that the focus of attention should move from PD models to other modeling problems in the credit industry including data quality, scorecard recalibration, variable selection, and LGD/EAD modeling.
Os autores recomendam empregar Random Forest (RF) como benchmark contra o qual comparar novos algoritmos de classificação. O HCES-Bag seria ainda mais difícil de ser batido, mas ainda não está amplamente disponível para consumo. Além disso, eles alertam contra a pratica de se comparar qualquer novo classificador apenas contra a regressão logística (RL). Esta é o padrão da indústria e é útil examinar como um novo classificador se compara à mesma. Dados, entretanto, os avanços documentados e o atual estado da arte, superar a RL não deve mais ser aceito como sinal indiscutível de progresso.