Collect training dataset, design an algorithm, train and finetune the model until it reaches the sufficient accuracy level. Usually it is done in Google Collab, Jupiter Notebook or DataSpell environment.
Eventually, save the model in format, compatible with your deployment environment.
• Save the model file in a persistent format (.pkl, .h5, .mod, etc.). • Develop a Dockerfile, requirements.txt, and any other necessary files. • Build a Docker container to encapsulate the model and its dependencies.
• Ensure you establish the required infrastructure • Create a REST API using framework like Flask, FastAPI, Django etc. • Deploy the API on a cloud service like Azure Web Services, AWS Fargate, Google Vertex, etc.
It is necessary to create a way to monitor the performance and behavior of the deployed model in real time. Also, set up alerts and logging to detect and address issues promptly. This will help while scaling and in development overall.
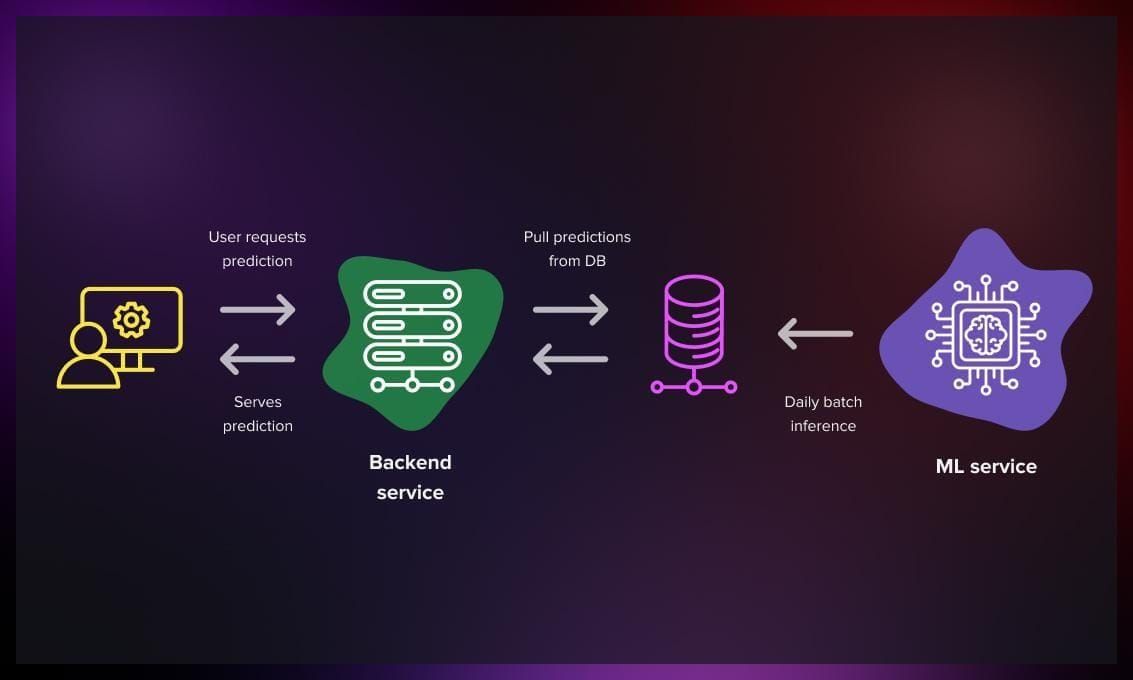
The model performs daily batch processing of predictions, after which they are returned to the service. While this method may result in slightly outdated data, it ensures that the data remains no more outdated than the last processed batch. This approach is ideal for situations where data is accumulated gradually over time and processed offline in larger batches.
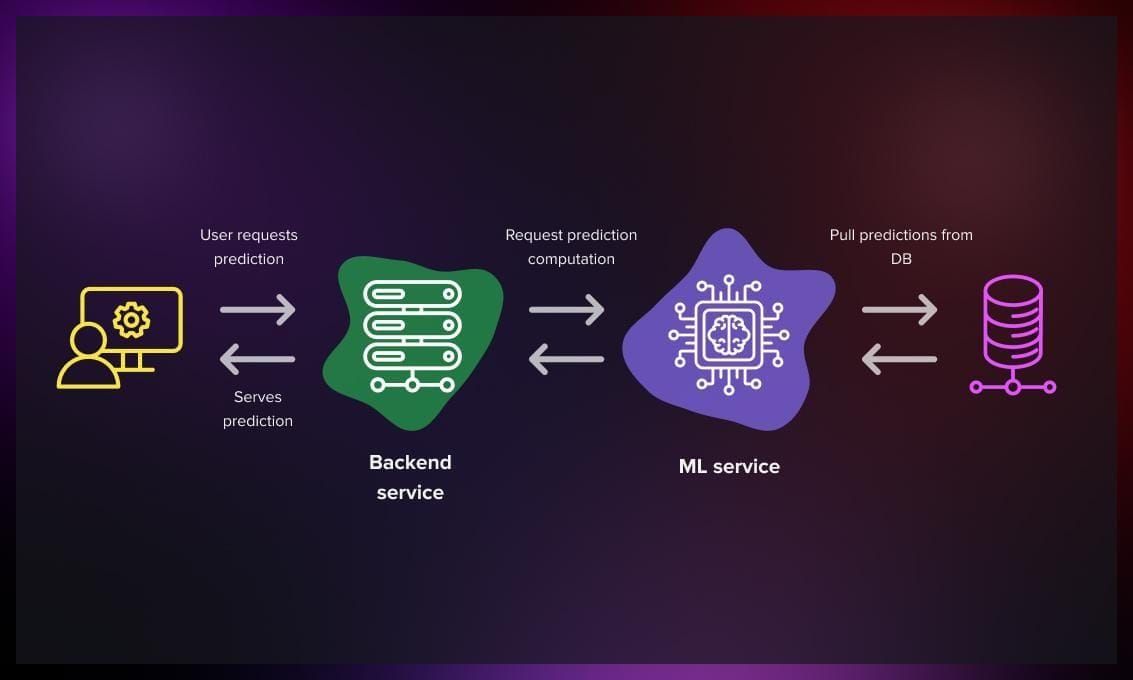
User requests prediction from Backend, it makes request to ML service (Rest API or microservice), which pulls data for prediction from database, computes the result and passes it back to user. It is effective for generating unique predictions from recent context, such as the time of day or recent user search queries. Requires multi-threaded processes and vertical scaling.
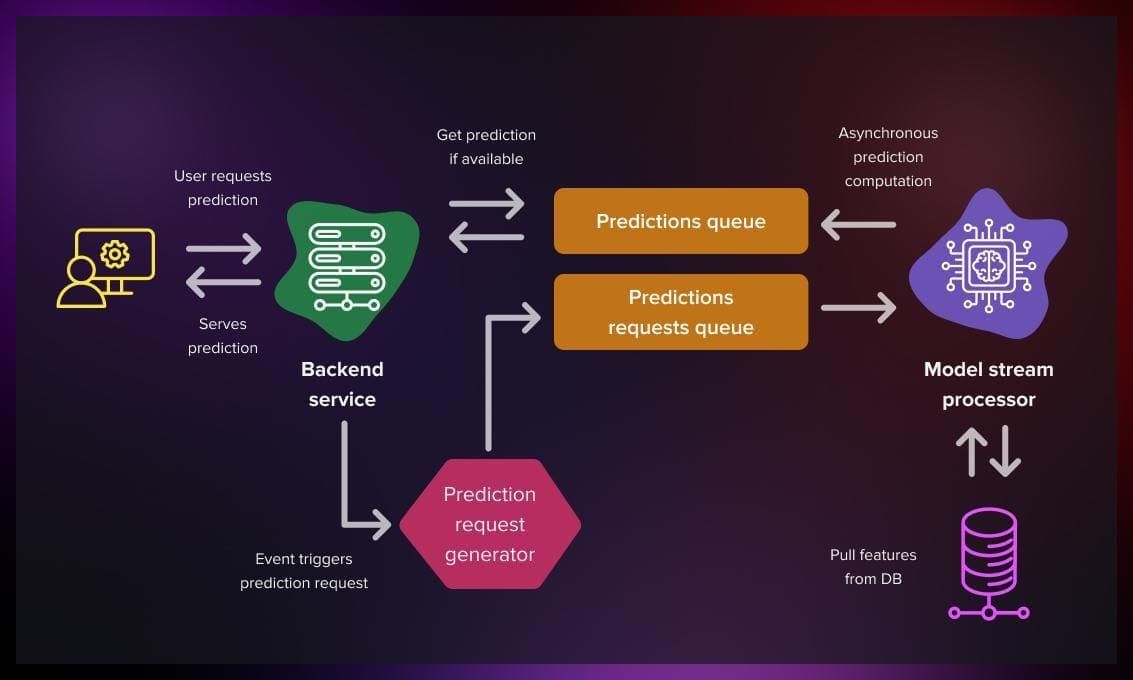
This is asynchronous approach, mostly used by recommendation systems nowadays. The procedure is incorporated within a message broker like Kafka. Once ready, the machine learning model handles the request. This method alleviates the server's processing load and enhances computational resource utilization via an effective queuing system. Moreover, prediction outcomes can be stored in the queue for the server's utilization as required.
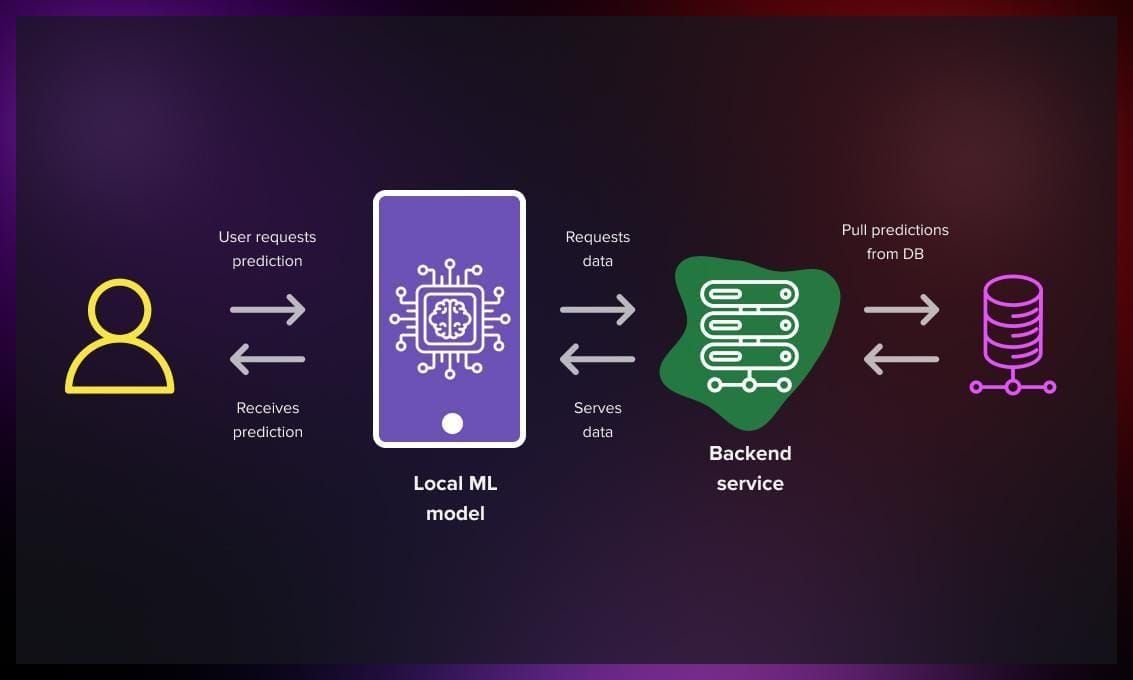
This approach has ML model installed on user local machine, so that developers don’t have to deal with scaling of ML service and enduser gets faster results and offline predictions. This involves using smaller model, and caching or quantization.
Three cornerstones to keep in mind are integrity, accessibility, and security.
Proper preprocessing techniques, such as normalization, feature scaling, and handling missing values, should be applied to prepare the data for model training. Additionally, data augmentation methods may be employed to increase the diversity and size of the training dataset.
Common storage solutions for ML data include relational databases, NoSQL databases, data lakes, and cloud storage services. The choice of storage solution depends on factors such as data volume, velocity, variety, and the need for real-time access.
Usually on ML model works one team (ML developers) and on its deployment works another (Backend developers). Another team will work on maintance and maybe on improving, so it is necessary to comment everything in a clear way, for example like this
Machine learning models frequently interact with sensitive information like customer data or financial records. It's imperative to prioritize the security and privacy of this data during model deployment. This entails implementing strong security protocols, encryption methods, access controls, and adherence to pertinent regulations. Such measures are vital for safeguarding the data and upholding user trust.
Continuous Integration/Continuous Delivery (CI/CD) encompasses a series of practices designed to automate build, test, and deploy software processes. Good example of CI/CD can be Modelbit. It offers a user-friendly, all-inclusive CI/CD stack featuring functionalities such as unit testing, model registry, and seamless integration with Git repositories.
Rest API
Docker
Machine Learning System Design
Appropriate Medium, PaperWithCode and Youtube content