Revisando el repositorio pattern.es me llama la atención el archivo es-spelling.txt tiene un diccionario gigantesco con palabras como clave y un valor numérico por ejemplo
'ultravioleta': 5
lo malo es que no explican para que es ese numero, solo dice
;;; Based on several public domain books from Project Gutenberg
;;; and Wikipedia articles and online Spanish newspaper articles.
entonces veamos donde lo usa
En el archivo __init__.pyen la parte
def suggest(w):
""" Returns a list of (word, confidence)-tuples of spelling corrections.
"""
return spelling.suggest(w)ahi lo usa para esa funcion que sugiere correcciones la variable spelling la define mas arriba
spelling = Spelling(
path = os.path.join(MODULE, "es-spelling.txt")
)es una instancia de esa clase que la importa de
# Import spelling base class.
from pattern.text import (
Spelling
)entonces vamos a pattern.text y vemos el __init__.py
y chusmeamos la clase
Ya se enrrosca un poco... Pero en este cometario
# Based on: Peter Norvig, "How to Write a Spelling Corrector", http://norvig.com/spell-correct.html
si seguimos el link
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probability of `word`."
return WORDS[word] / NViendo eso me doy cuenta que en realidad el archivo es-spelling.txt no contiene un diccionario común si no un Counter
Por lo tanto el numerito de los values() de es-spelling.txt es un contador de la cantidad de veces que apareció la palabra en el entrenamiento quetuvo el paquete, como decia al principio,
;;; Based on several public domain books from Project Gutenberg
;;; and Wikipedia articles and online Spanish newspaper articles.Me fuí un poco por las ramas, pero bueno es útil esa función suggest para el trabajo si se quiere corregir las palabras.
Más importate que todo esto es otro archivo que se encuentra en pattern.es, el lexicon.
Es tan grande que el visor de github no lo carga y hay que verlo en raw.
vemos que tiene palabras junto con lo que parece ser el part_of_speech, por ej ballet NCS. Antes revisemos que es NCS. en la lista de abreviaciones
Lo malo es que no aparece allí. Tampoco aparece en ninguno de estos "tag sets". El único resultado alegórico lo encuentro en este paper donde la sigla hace referencia al termino en ingles Noun Compounds, o sea sustantivos compuestos, lo cual en mi opinión ballet no es, pero bueno sigamos mirando que más tiene lexicon
En el __init__.py
lexicon = parser.lexicon # Expose lexicon.Por lo tanto es otro atributo digamos del paquete. Vamos a hacer una prueba, importo pattern "a lo bruto" sin from a ver que imprimen estas cosas:
>>> import pattern.es
>>> print(type(pattern.es.spelling))
<class 'pattern.text.Spelling'>
>>> print(dir(pattern.es.spelling))
['CYRILLIC', 'LATIN', '__class__', '__contains__', '__delattr__','__delitem__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__','__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_edit1', '_edit2', '_known','_lazy', '_path', 'alphabet', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'language', 'load', 'path', 'pop', 'popitem', 'setdefault', 'suggest', 'train', 'update', 'values']
>>>Si bien el tipo es raro, tiene el metodo keys, lo mismo con pattern.es.lexicon entonces probemos este programa:
import pattern.es
dir(pattern.es)
c = 0
for x in pattern.es.lexicon.keys():
if x in pattern.es.spelling.keys():
print(x, end=', ')
c += 1
print('Cantidad de palabras en lexicon que no estan en spelling: ',c)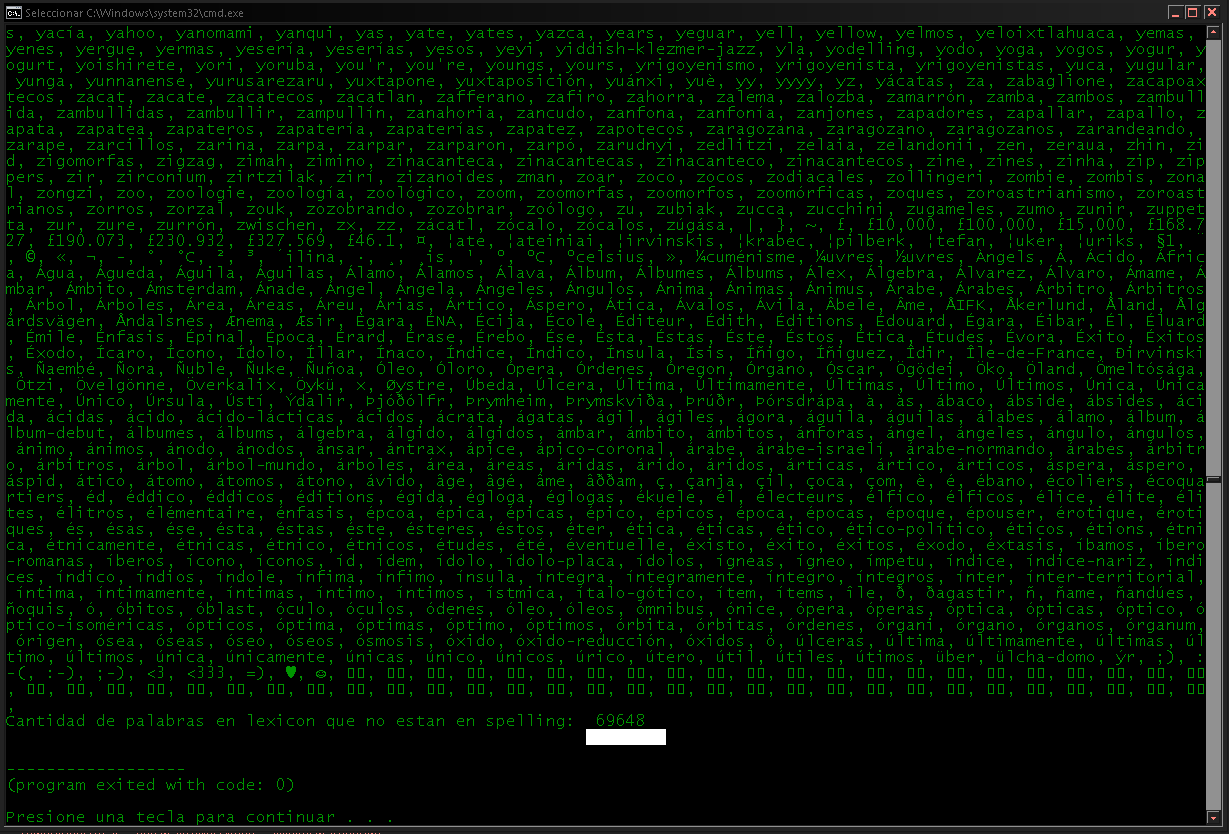
c = 0
for x in pattern.es.spelling.keys():
if not(x in pattern.es.lexicon.keys()):
print(x, end=', ')
c += 1
print()
print('Cantidad de palabras en spelling que no estan en lexicon: ',c)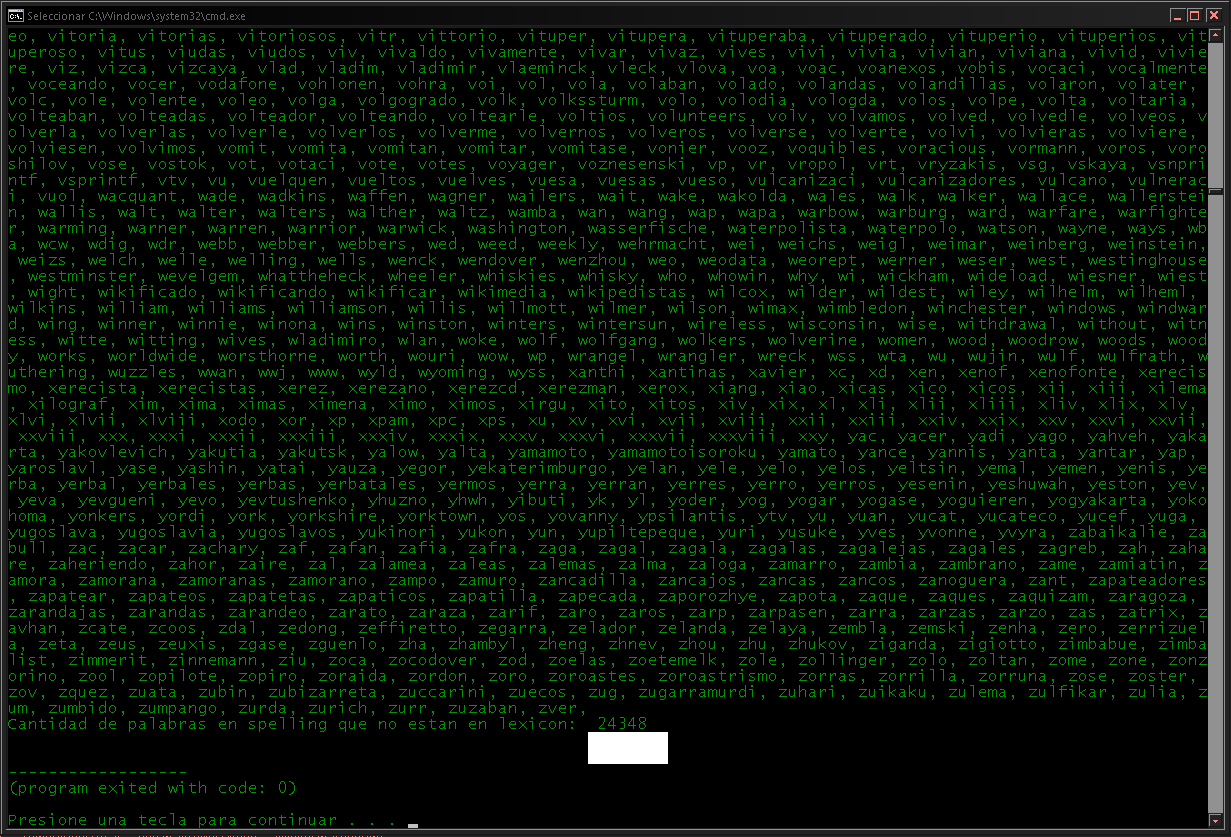
Como vemos son archivos disjuntos, lexicon tiene símbolos mas raros , pero spelling también tiene palabras en otros idiomas y casos raros como por ejemplo no está 'zanahoria' pero si 'zanahorias' Busquemos las entradas más largas de cada archivo:
lista = list(pattern.es.spelling.keys())
mas_largo = max(lista, key=len)
print(mas_largo,' - ', len(mas_largo))nos da
bienintencionadamente - 21
pero con lexicon obtenemos:
....................................................................... - 71
Es gracioso que sin la key=len da 🙀 🙀
Perdón, seguimos,
from collections import Counter
c = Counter(pattern.es.lexicon.values())
print(c)Si cuento los distintos valores del diccionario veo:
Counter({'NP': 23462, 'NCS': 13780, 'AQ': 11017, 'VMI': 9016,
'NCP': 7568, 'Z': 5969, 'VMP': 5259, 'VMN': 2206, 'RG': 1731,
'VMS': 1485, 'VMG': 1258, 'NC': 1082, 'Zu': 441, 'W': 295,
'VMM': 249, 'I': 161, 'Zp': 130, 'SP': 111, 'DI': 74, 'SYM': 63,
'Zm': 59, 'AO': 56, 'VAI': 54, 'Fz': 48, 'PP': 42, 'DD': 29,
'VSI': 27, 'Zd': 25, 'DP': 25, 'PI': 21, 'CC': 21,'PD': 20,
'PR': 16, 'PT': 16, 'CS': 15, 'VAS': 15, 'DA': 13, 'VSS': 9,
'Fs': 6, 'PX': 6, 'Fe': 4, 'Fc': 3, 'VAG': 3, 'VAN': 3, 'Fa': 2,
'"': 2, 'Fg': 2, 'Fh': 2, 'Fr': 2, 'Fi': 2, 'DT': 2, 'RN': 2,
'P0': 2, 'VSN': 2, 'VSG': 2, 'Fpa': 1, 'Fpt': 1, 'Fp': 1, 'Fd': 1,
'Fx': 1, 'VSP': 1, 'Fl': 1})Por lo que vuelve a surgir la duda de qué significaran esos tags ya que no se encuentran en la tabla proporcionada por pattern.
Pero viendo la definicion de parse
parse(string,
tokenize = True, # Split punctuation marks from words?
tags = True, # Parse part-of-speech tags? (NN, JJ, ...)
chunks = True, # Parse chunks? (NP, VP, PNP, ...)
relations = False, # Parse chunk relations? (-SBJ, -OBJ, ...)
lemmata = False, # Parse lemmata? (ate => eat)
encoding = 'utf-8' # Input string encoding.
tagset = None) # Penn Treebank II (default) or UNIVERSAL.Creo que UNIVERSAL se refiere a ese otro tagset que vemos en lexicon. Voy a probar:
for x in lexicon:
if lexicon[x] != tag(x, tokenize=True, encoding='utf-8',tagset = 'UNIVERSAL')[0][1]:
print(x, end=', ')#11, #12-438-512, #12-439-610, #13, #136, #14, #15, #16, #19, #20, #21, #22, #228, #23, #24, #25, #26, #27, #28, #285, #
29, #30, #31, #32, #33, #34, #344, #35, #36, #360, #361, #37, #38, #400, #42, #45, #50, #55, #61, #62, #63, #75, #83, #8
6, #89, #93, #94, #96, $1.99, $13, $150, $200, $29,00, $3,000, $300, $37,000,000.00, $380,9, $4.03, $49, $50, $507,933,0
00, $58.59, $6.79, $60, $600.000, $70.60, $785, $79, $924.9, $93,7, &fmt=18, &fmt=22, *100, *18, *1929, *1ª, +-120, +10,
+100.000, +12, +15, +20, +20/-20, +22, +30, +300.000, +33, +34, +44, +80.000, ,1999, ,2002, ---, ----, -//W3C//DTD, -00
198, -10, -1073, -1080, -1085, -11, -1150, -1160, -1190, -12, -1210, -1211, -1214, -1217, -1244, -1255, -1292, -13, -134
7, -14, -15, -16, -1732, -1767, -1884, -1886, -1906, -1914, -1940, -20, -20º, -20ºC, -29, -30, -32, -320, -350, -40, -50
, -67, -6º, -6ºC, -7º, -8ºC, ..., ...., ....., ......, ............................, ............................., ....
............................., ........................................., ............................................,
.............................................., ................................................., .....................
..................................., ..................................................................., ..............
........................................................., .000, .000.000, .182, .256, .323, .346, .359, .380, .382, .38
5, .396, .401, .403, .412, .424, .438, .444, .446, .452, .464, .471, .477, .480, .483, .488, .494, .500, .514, .536, .54
2, .557, .585, .616, .750, .786, .7z, .824, .833, .848, .850, .853, .855, .856, .860, .892, 024.htm;, 4.php;, Col., EE.U
U., Mar., Sto., Vols., arts., co., col., ed., id., id=242101545;, id=242101995;, ms., o.shtml;, pH., pl., pm., secret.,
vols., www.casadelaveiga.com;, www.cultura-sorda.eu;, www.difilm.com.ar),, www.distritodellama.com;, www.divinavoluntad.
net;, www.el-guijo.es;, www.eurekared.com),, www.gesualdo.eu;, www.ibelieveinharveydent.com", www.kedainiai.info;, www.k
edainiai.lt;, www.lfp.es;, www.mercedaragon.org;, www.mercedarios.cl;, www.mercedarios.com;, www.mercedarios.net;, www.m
osovce.sk;, www.odemira.net;, www.samadegrado.es;, www.startalk.ch;,
Esto quiere decir que exepto esas cosas raras que estan ahi todo lo demás son palabras que tienen su respectivo tag. 179 Por lo tanto para filtrar deberíamos buscar que esté en alguno de los dos conjunto spelling o lexicon y si es asi lo tageamos con uno de los dos sistemas
from pattern.es import lexicon, spelling, tag
def clasificar(palabra):
print(tag(palabra, tokenize=True, encoding='utf-8', tagset = 'UNIVERSAL'))
print(tag(palabra, tokenize=True, encoding='utf-8'))
palabra = 'azucar'
if not palabra in spelling:
if not palabra in lexicon:
print('No se encuentra en pattern.es')
else:
print('La encontró en lexicon')
clasificar(palabra)
else:
print('La encontró en spelling')
clasificar(palabra)Camino
La encontró en lexicon
[('Camino', 'NCS')]
[('Camino', 'NN')]
camion
No se encuentra en pattern.es
camión
La encontró en lexicon
[('camión', 'NCS')]
[('camión', 'NN')]
vurro
No se encuentra en pattern.es
burro
La encontró en spelling
[('burro', 'NCS')]
[('burro', 'NN')]
Burro
No se encuentra en pattern.es
BURRO
No se encuentra en pattern.es
Argentina
La encontró en lexicon
[('Argentina', 'NP')]
[('Argentina', 'NNP')]
argentina
La encontró en spelling
[('argentina', 'AQ')]
[('argentina', 'JJ')]
ARGENTINA
No se encuentra en pattern.esNo es perfecto, ya que algunos terminos específicos no los encuentra y hay que filtrar las mayúsculas, no todas, ya que los sustantivos propios en lexicon estan con mayuscula. Pero bueno mejoró.
Además hay otra lista de palabras: verbs que tiene pocas palabras en relación a los otros, pero con mas razónn me sirve como fusible para buscar en ella primero que es más rápido.
from pattern.es import verbs, tag, spelling, lexicon
import string
def clasificar(palabra):
print( tag(palabra, tokenize=True, encoding='utf-8',tagset = 'UNIVERSAL'))
print( tag(palabra, tokenize=True, encoding='utf-8'))
print()
palabra = 'Camino'
print(palabra)
while palabra != 'q':
if not palabra.lower() in verbs:
if not palabra.lower() in spelling:
if (not(palabra.lower() in lexicon) and not(palabra.upper() in lexicon) and not(palabra.capitalize() in lexicon)):
print('No se encuentra en pattern.es')
else:
print('La encontró en lexicon')
clasificar(palabra)
else:
print('La encontró en spelling')
clasificar(palabra)
else:
print('La encontró en verbs')
clasificar(palabra)
print()
palabra = input()BURRO
La encontró en spelling
[('BURRO', 'NCS')]
[('BURRO', 'NN')]
Manco
La encontró en spelling
[('Manco', 'NP')]
[('Manco', 'NNP')]
ArMoNíA
La encontró en lexicon
[('ArMoNíA', 'NCS')]
[('ArMoNíA', 'NN')]
BaILAr
La encontró en verbs
[('BaILAr', 'VMN')]
[('BaILAr', 'VB')]
djjd
No se encuentra en pattern.es