-
Notifications
You must be signed in to change notification settings - Fork 2.3k
Expand file tree
/
Copy pathhashcode.md
More file actions
243 lines (177 loc) · 13.4 KB
/
hashcode.md
File metadata and controls
243 lines (177 loc) · 13.4 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
---
title: Java hashCode方法深入解析
shortTitle: Java hashCode方法解析
category:
- Java核心
tag:
- Java重要知识点
description: hashCode是Java 所有类都有的方法,它会返回一个整数哈希码,表示对象在内存中的近似位置。相等的对象应具有相同哈希码,因此自定义类时需同时重写hashCode()和equals()方法。
author: 沉默王二
head:
- - meta
- name: keywords
content: java,hashcode,equals
---
今天我们来谈谈 Java 中的 `hashCode()` 方法。众所周知,Java 是一门面向对象的编程语言,所有的类都会默认继承自 Object 类,而 Object 的中文意思就是“对象”。
Object 类中就包含了 `hashCode()` 方法:
```java
public native int hashCode();
```
意味着所有的类都会有一个 `hashCode()` 方法,该方法会返回一个 int 类型的值。由于 `hashCode()` 方法是一个[本地方法](https://javabetter.cn/oo/native-method.html)(`native` 关键字修饰的方法,用 `C/C++` 语言实现,由 Java 调用),意味着 Object 类中并没有给出具体的实现。
具体的实现可以参考 `jdk/src/hotspot/share/runtime/synchronizer.cpp`(源码可以到 [GitHub 上 OpenJDK 的仓库中下载](https://github.com/openjdk/jdk/blob/master/src/hotspot/share/runtime/synchronizer.cpp))。`get_next_hash()` 方法会根据 hashCode 的取值来决定采用哪一种哈希值的生成策略。
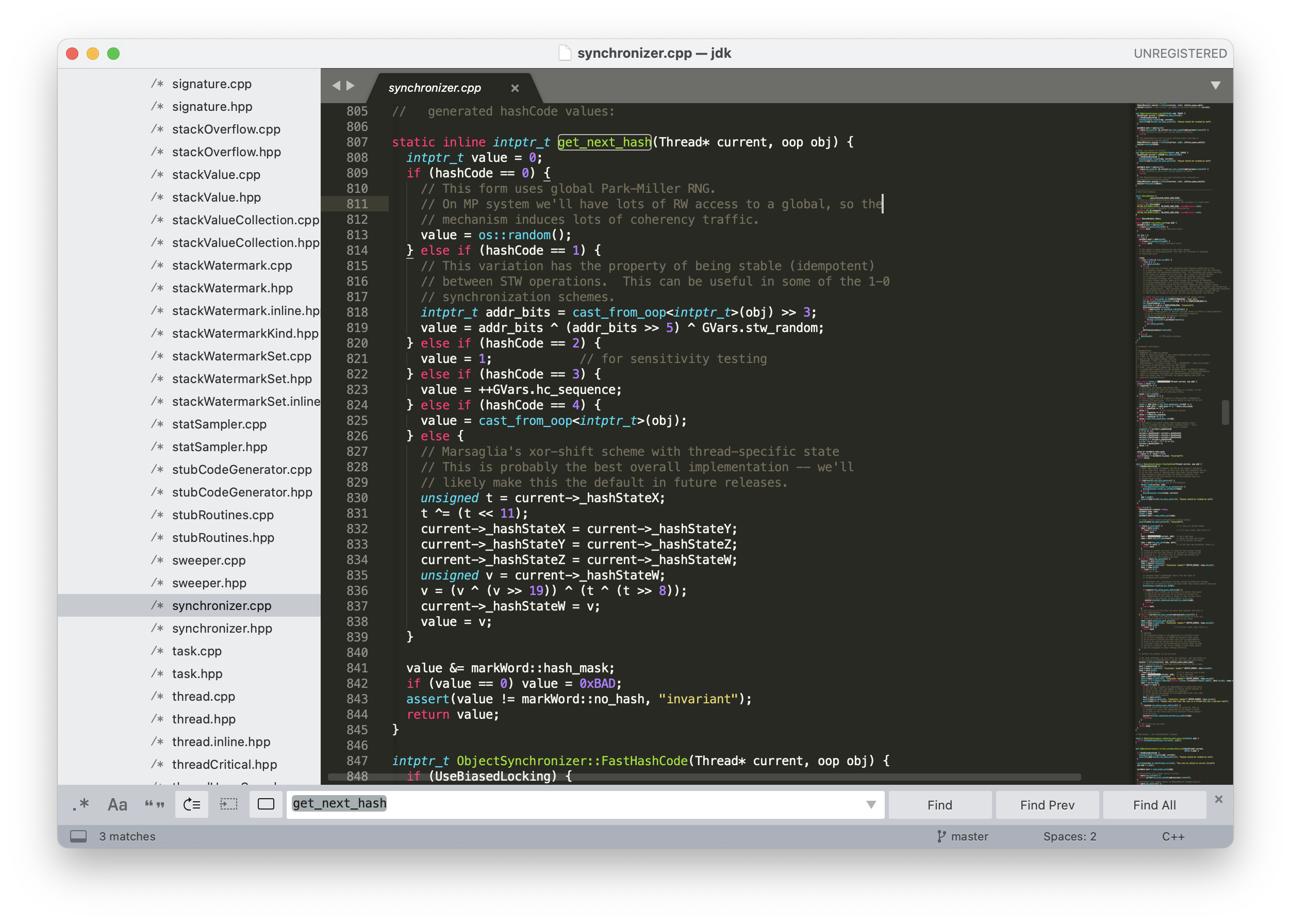
Java 9 之后,`hashCode()` 方法会被 `@HotSpotIntrinsicCandidate` 注解修饰,表明它在 HotSpot 虚拟机中有一套高效的实现,基于 CPU 指令。
那大家有没有想过这样一个问题:**为什么 Object 类需要一个 `hashCode()` 方法呢**?
在 Java 中,`hashCode()` 方法的主要作用就是为了配合[哈希表](https://javabetter.cn/collection/hashmap.html)使用的。
哈希表(Hash Table),也叫散列表,是一种可以通过关键码值(key-value)直接访问的数据结构,它最大的特点就是可以快速实现查找、插入和删除。其中用到的算法叫做哈希,就是把任意长度的输入,变换成固定长度的输出,该输出就是哈希值。像 MD5、SHA1 都用的是哈希算法。
像 Java 中的 HashSet、Hashtable(注意是小写的 t)、HashMap 都是基于哈希表的具体实现。其中的 [HashMap](https://javabetter.cn/collection/hashmap.html) 就是最典型的代表,不仅面试官经常问,工作中的使用频率也非常的高。
大家想一下,如果没有哈希表,但又需要这样一个数据结构,它里面存放的数据是不允许重复的,该怎么办呢?
要不使用 `equals()` 方法进行逐个比较?这种方案当然是可行的。但如果数据量特别特别大,采用 `equals()` 方法进行逐个对比的效率肯定很低很低,最好的解决方案就是哈希表。
拿 HashMap 来说吧。当我们要在它里面添加对象时,先调用这个对象的 `hashCode()` 方法,得到对应的哈希值,然后将哈希值和对象一起放到 HashMap 中。当我们要再添加一个新的对象时:
- 获取对象的哈希值;
- 和之前已经存在的哈希值进行比较,如果不相等,直接存进去;
- 如果有相等的,再调用 `equals()` 方法进行对象之间的比较,如果相等,不存了;
- 如果不等,说明哈希冲突了,增加一个链表,存放新的对象;
- 如果链表的长度大于 8,转为红黑树来处理。
就这么一套下来,调用 `equals()` 方法的频率就大大降低了。也就是说,只要哈希算法足够的高效,把发生哈希冲突的频率降到最低,哈希表的效率就特别的高。
来看一下 HashMap 的哈希算法:
```java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
先调用对象的 `hashCode()` 方法,然后对该值进行右移运算,然后再进行异或运算。
通常来说,String 会用来作为 HashMap 的键进行哈希运算,因此我们再来看一下 String 的 `hashCode()` 方法:
```java
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
```
可想而知,经过这么一系列复杂的运算,再加上 JDK 作者这种大师级别的设计,哈希冲突的概率我相信已经降到了最低(我们在 HashMap 中深入探讨过)。
当然了,从理论上来说,对于两个不同对象,它们通过 `hashCode()` 方法计算后的值可能相同。因此,不能使用 `hashCode()` 方法来判断两个对象是否相等,必须得通过 `equals()` 方法。
也就是说:
- 如果两个对象调用 `equals()` 方法得到的结果为 true,调用 `hashCode()` 方法得到的结果必定相等;
- 如果两个对象调用 `hashCode()` 方法得到的结果不相等,调用 `equals()` 方法得到的结果必定为 false;
反之:
- 如果两个对象调用 `equals()` 方法得到的结果为 false,调用 `hashCode()` 方法得到的结果不一定不相等;
- 如果两个对象调用 `hashCode()` 方法得到的结果相等,调用 `equals()` 方法得到的结果不一定为 true;
来看下面这段代码。
```java
public class Test {
public static void main(String[] args) {
Student s1 = new Student(18, "张三");
Map<Student, Integer> scores = new HashMap<>();
scores.put(s1, 98);
System.out.println(scores.get(new Student(18, "张三")));
}
}
class Student {
private int age;
private String name;
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public boolean equals(Object o) {
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
}
```
我们重写了 Student 类的 `equals()` 方法,如果两个学生的年纪和姓名相同,我们就认为是同一个学生,虽然很离谱,但我们就是这么草率。
在 `main()` 方法中,18 岁的张三考试得了 98 分,很不错的成绩,我们把张三和成绩放到了 HashMap 中,然后准备输出张三的成绩:
```
null
```
很不巧,结果为 null,而不是预期当中的 98。这是为什么呢?
原因就在于重写 `equals()` 方法的时候没有重写 `hashCode()` 方法。默认情况下,`hashCode()` 方法是一个本地方法,会返回对象的存储地址,显然 `put()` 中的 s1 和 `get()` 中的 `new Student(18, "张三")` 是两个对象,它们的存储地址肯定是不同的。
HashMap 的 `get()` 方法会调用 `hash(key.hashCode())` 计算对象的哈希值,虽然两个不同的 `hashCode()` 结果经过 `hash()` 方法计算后有可能得到相同的结果,但这种概率微乎其微,所以就导致 `scores.get(new Student(18, "张三"))` 无法得到预期的值 18。
怎么解决这个问题呢?很简单,重写 `hashCode()` 方法。
```java
@Override
public int hashCode() {
return Objects.hash(age, name);
}
```
[Objects 类](https://javabetter.cn/common-tool/Objects.html)的 `hash()` 方法可以针对不同数量的参数生成新的 `hashCode()` 值。
```java
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
```
代码似乎很简单,归纳出的数学公式如下所示(n 为字符串长度)。
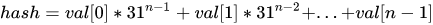
注意:31 是个奇质数,不大不小,一般质数都非常适合哈希计算,偶数相当于移位运算,容易溢出,造成数据信息丢失。
这就意味着年纪和姓名相同的情况下,会得到相同的哈希值。`scores.get(new Student(18, "张三"))` 就会返回 98 的预期值了。
《Java 编程思想》这本圣经中有一段话,对 `hashCode()` 方法进行了一段描述。
> 设计 `hashCode()` 时最重要的因素就是:无论何时,对同一个对象调用 `hashCode()` 都应该生成同样的值。如果在将一个对象用 `put()` 方法添加进 HashMap 时产生一个 `hashCode()` 值,而用 `get()` 方法取出时却产生了另外一个 `hashCode()` 值,那么就无法重新取得该对象了。所以,如果你的 `hashCode()` 方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,`hashCode()` 就会生成一个不同的哈希值,相当于产生了一个不同的键。
也就是说,如果在重写 `hashCode()` 和 `equals()` 方法时,对象中某个字段容易发生改变,那么最好舍弃这些字段,以免产生不可预期的结果。
好。有了上面这些内容作为基础后,我们回头再来看看本地方法 `hashCode()` 的 C++ 源码。
```cpp
static inline intptr_t get_next_hash(Thread* current, oop obj) {
intptr_t value = 0;
if (hashCode == 0) {
// 这种形式使用全局的 Park-Miller 随机数生成器。
// 在 MP 系统上,我们将对全局变量进行大量的读写访问,因此该机制会引发大量的一致性通信。
value = os::random();
} else if (hashCode == 1) {
// 这种变体在 STW(Stop The World)操作之间具有稳定(幂等)的特性。
// 在一些 1-0 同步方案中,这可能很有用。
intptr_t addr_bits = cast_from_oop<intptr_t>(obj) >> 3;
value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random;
} else if (hashCode == 2) {
value = 1; // 用于敏感性测试
} else if (hashCode == 3) {
value = ++GVars.hc_sequence;
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj);
} else {
// Marsaglia 的异或移位方案,具有线程特定的状态
// 这可能是最好的整体实现 -- 我们可能会在未来的版本中将其设为默认实现。
unsigned t = current->_hashStateX;
t ^= (t << 11);
current->_hashStateX = current->_hashStateY;
current->_hashStateY = current->_hashStateZ;
current->_hashStateZ = current->_hashStateW;
unsigned v = current->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
current->_hashStateW = v;
value = v;
}
value &= markWord::hash_mask;
if (value == 0) value = 0xBAD;
assert(value != markWord::no_hash, "invariant");
return value;
}
```
如果没有 C++ 基础的话,不用细致去看每一行代码,我们只通过表面去了解一下 `get_next_hash()` 这个方法就行。其中的 `hashCode` 变量是 JVM 启动时的一个全局参数,可以通过它来切换哈希值的生成策略。
- `hashCode==0`,调用操作系统 OS 的 `random()` 方法返回随机数。
- `hashCode == 1`,在 STW(stop-the-world)操作中,这种策略通常用于同步方案中。利用对象地址进行计算,使用不经常更新的随机数(`GVars.stw_random`)参与其中。
- `hashCode == 2`,使用返回 1,用于某些情况下的测试。
- `hashCode == 3`,从 0 开始计算哈希值,不是线程安全的,多个线程可能会得到相同的哈希值。
- `hashCode == 4`,与创建对象的内存位置有关,原样输出。
- `hashCode == 5`,默认值,支持多线程,使用了 Marsaglia 的 xor-shift 算法产生伪随机数。所谓的 xor-shift 算法,简单来说,看起来就是一个移位寄存器,每次移入的位由寄存器中若干位取异或生成。所谓的伪随机数,不是完全随机的,但是真随机生成比较困难,所以只要能通过一定的随机数统计检测,就可以当作真随机数来使用。
这里简单总结下。
在 Java 中,`hashCode()`方法是定义在 `java.lang.Object` 类中的一个方法,该类是所有 Java 所有类的父类。因此,每个 Java 对象都可以调用 `hashCode()`方法。`hashCode()`方法主要用于支持哈希表(如 java.util.HashMap),这些数据结构使用哈希算法能实现快速查找、插入和删除操作。
`hashCode()`方法的主要目的是返回一个整数,这个整数称为哈希码,它代表了对象在内存中的一种近似表示。哈希码用于将对象映射到哈希表中的一个特定的位置。两个相等的对象(根据 [`equals()`方法比较](https://javabetter.cn/string/equals.html))应该具有相同的哈希码。然而,具有相同哈希码的两个对象并不一定相等。
当你创建一个自定义类并覆盖 `equals()`方法时,通常也需要覆盖 `hashCode()`方法,以确保相等的对象具有相同的哈希码。这有助于提高哈希表在使用自定义类的对象作为键时的准确性。
---
GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
