Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据,属于信息时代获取数据必备神器。淘宝、天猫、亚马逊等电商网站商品信息、知乎回答列表、微博热门、微博评论、博客文章列表等等,只有你想不到,没有它办不到的!
写在做前面
Webscraper是一位叫“明白”的大佬发现,并分享了它的详细操作。明白老师创建了知识星球精选站http://www.zsxq100.com/,创建了Webscraper中文网http://www.iwebscraper.com。如果从网页抓取数据是你的工作,那你可以选择学习明白老师的关于Webscraper的爬虫课程。课程所讲的内容如下:
有兴趣的朋友可以详细的学习一下Webscraper抓取网页数据。扫描下面的二维码即可进入他的课程。
明白老师也是善于善于思考,乐于分享他的赚钱之道的人。他的知识星球有一个付费的和一个免费的,有兴趣的朋友可以加入一下,进入大佬的圈子。
安装地址:
https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn?hl=en(注:不用代理工具的小伙伴,可能访问不了,获取免费的代理工具,关注我的公众号“不安分的猿人”,回复“科学上网”,即可获取上网插件)
当然,你也可以通过这里获取插件:https://pan.baidu.com/s/133qCd3Bb9gaapqxcRk7aGw 提取码: kg61
google浏览器安装插件这里就略过了。
以抓取知乎大V陈素封文章前 3 页标题、正文全文、点赞数为例。(https://www.zhihu.com/people/Feat/posts)
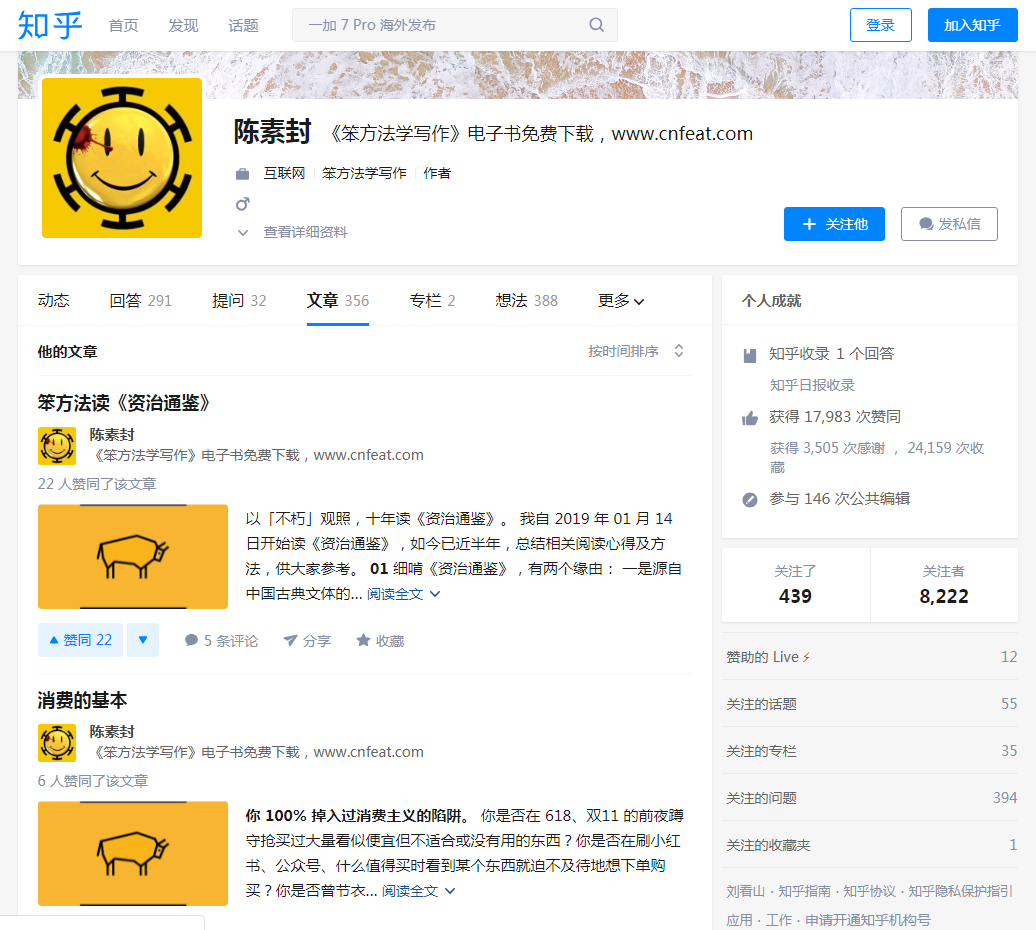

1.抓取流程
1)第一步:了解网址规则,建立 Sitemap,名称可根据每个人的习惯自己来定义。

2)第二步:熟悉网页结构,按下图顺序创建选择器。


为元素选择器 post-element 建立 3 个子选择器,分别为文本选择器post-title、链接选择器full-content-link、文本选择器link-count。



2.操作技巧
1.鼠标选择要抓取的元素,制定抓取规则;

2.检查写好的选择器是否正确,可点击“Element preview”按钮,对数据进行预览。


3.导出siteMap
{
"_id": "chensufeng-zhihu-post",
"startUrl": [
"https://www.zhihu.com/people/Feat/posts?page=[1-3]"
],
"selectors": [
{
"id": "post-element",
"type": "SelectorElement",
"parentSelectors": [
"_root"
],
"selector": "div.List-item",
"multiple": true,
"delay": 0
},
{
"id": "post-title",
"type": "SelectorText",
"parentSelectors": [
"post-element"
],
"selector": "h2.ContentItem-title a",
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "full-content-link",
"type": "SelectorLink",
"parentSelectors": [
"post-element"
],
"selector": "h2.ContentItem-title a",
"multiple": false,
"delay": 0
},
{
"id": "link-count",
"type": "SelectorText",
"parentSelectors": [
"post-element"
],
"selector": "span.Voters button.Button",
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "post-full-content",
"type": "SelectorText",
"parentSelectors": [
"post-element"
],
"selector": "span.RichText ",
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "test1",
"type": "SelectorText",
"parentSelectors": [
"post-element"
],
"selector": ".Voters button",
"multiple": false,
"regex": "",
"delay": 0
}
]
}
4.数据导出
Web Scraper 支持将数据导出为excel,也支持将数据导出到CouchDB (一个面向文档的数据库 )。
八爪鱼,官网:https://www.bazhuayu.com/
后羿采集器:官网:http://www.houyicaiji.com/
GooSeeker (集搜客),官网:http://www.jisouke.com/
Web Scraper 官方文档中文版.pdf文档
百度链接: https://pan.baidu.com/s/1fYRi8B4irtMqvlgV0Ix5Jg 提取码: cv43
