Before we dive deep into the concept of Word Embedding,it is important to have a basic idea of Natural Language Processing. So lets have a small introduction,shall we?
- In simple words,NLP is how computers perceive and analyze the languages,which we use to communicate with each other

- It has tons of applications ,from Amazon Alexa that we use in our homes to the Swiggy chatbots that we talk to while tracking our ordered food!
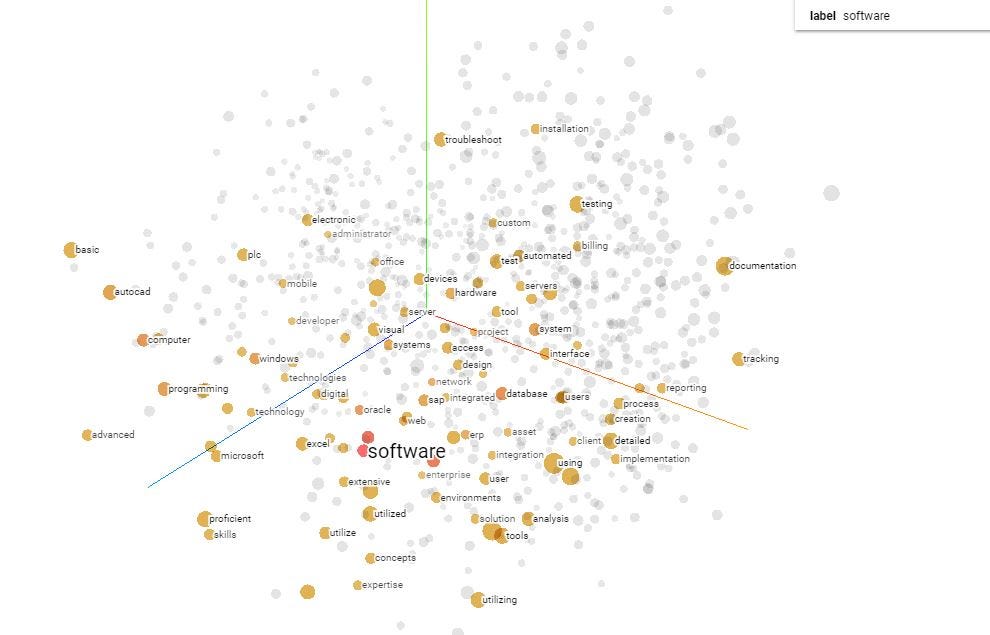
- Word embeddings is nothing but representation of words in the form of vectors where words having similar meaning point to the same direction
- For example,the vectors of the words such as important,essential and crucial may point in the same direction as they have similar meanings,so they are grouped together

-
Looks interesting ,but how does it happen?
- Let's understand the procedure through an interesting project which I did last month,using a dataset called ''IMDB Reviews''
- This dataset basically contains thousands of sentences of reviews(called features) of different movies on the IMDB website given by different people ,and along with type of the corresponding review ,0 for bad and 1 for a good review (called labels)
- This data was fed into a neural network(Deep Learning),in order to analyze the words in these sentences which corresponds to the type of review ,i.e,positive or negative
- After the model was done training on the data,it could predict on never seen text(review) given by us ,whether it is a negative or a positive one!
- As shown above,using an embedding projector(which is easily available online),we can view the projections of these words,where similar words are grouped together!Looks cool,doesn't it?
-
The datasets used may vary ,as it may be used for a different application**,say Sarcasm Detection,but the concept pretty much reamins the same*.